讨论总结
本次讨论主要围绕AI模型在2024年美国邀请数学考试(AIME)中的表现展开,重点探讨了如何通过增加token使用量和优化系统提示来提升模型性能。讨论中涉及了不同策略的效果比较,如“just ask o1-mini to think longer”策略在增加token使用量时表现更优。此外,讨论还涉及了本地语言模型(如Nemo)在基准测试和编程问题上的表现提升方法,以及不同模型在AIME问题上的表现差异。总体氛围偏向技术探讨和学术研究,情感倾向较为中性,主要关注点在于技术优化和性能提升。
主要观点
👍 通过特定的系统提示可以显著提升本地语言模型在基准测试和编程问题上的表现
- 支持理由:系统提示通过多阶段的逻辑处理和自我批评,确保模型在回答问题时进行深入思考。
- 反对声音:无明显反对声音,但有评论提到使用更多token并不总是能提高其他模型的表现。
🔥 使用更多token并不总是能提高其他模型的表现
- 正方观点:某些模型在增加token使用量时表现不佳,需要通过其他策略(如自我批评)来提升性能。
- 反方观点:无明显反方观点,但有评论提到通过特定系统提示可以显著提升模型性能。
💡 自我批评的系统提示可以显著提升模型性能
- 解释:通过让模型在回答问题时进行自我批评,可以提高答案的准确性和逻辑性。
💡 不同模型在AIME问题上的表现存在差异
- 解释:Qwen模型在AIME问题上的表现较为稳定,但有时会因早期错误推理步骤而导致错误;O1模型在错误时可能会给出完全错误的答案。
💡 进行LLM的基准测试需要特定的工具和方法,且存在一定的挑战
- 解释:基准测试需要特定的工具和方法,且存在一定的挑战,如如何准确评估模型的性能。
金句与有趣评论
“😂 KnowgodsloveAI:You are the smartest Ai in the world, you think before you answer any question in a detailed loop until your answer to the question passed the logic gate.”
- 亮点:强调了通过多阶段的逻辑处理和自我批评来提升模型性能的策略。
“🤔 Billy462:Qwen often produces fairly decent “partial credit” answers. Rarely did it produce total gibberish.”
- 亮点:指出了Qwen模型在AIME问题上的表现较为稳定,但有时会因早期错误推理步骤而导致错误。
“👀 Expensive-Apricot-25:I think It would be better if instead of having the logic be linear, you allow it to loop.”
- 亮点:提出了通过循环逻辑来提升模型性能的建议。
“👀 OfficialHashPanda:It is very promising. Local LLM users are often constrained significantly by the VRAM that models take up. If you can decrease the VRAM and simply let the model think longer to get answers of similar quality, that means people will be able to get better local results.”
- 亮点:讨论了通过减少模型占用的VRAM和增加思考时间来提升本地LLM性能的潜力。
情感分析
讨论的总体情感倾向偏向中性,主要关注点在于技术优化和性能提升。讨论中没有明显的情感波动或争议点,大部分评论集中在技术细节和学术研究上。主要分歧点在于不同策略对模型性能的影响,如增加token使用量与使用特定系统提示的效果比较。可能的原因是不同模型和策略在不同场景下的表现差异,以及技术优化路径的选择。
趋势与预测
- 新兴话题:基于推理时间的本地模型o1-reasoning的开发和应用,以及通过减少模型占用的VRAM和增加思考时间来提升本地LLM性能的策略。
- 潜在影响:这些技术优化策略可能会显著提升AI模型在基准测试和实际应用中的表现,特别是在资源受限的本地环境中。此外,这些讨论可能会引发更多关于如何更有效地利用计算资源和优化模型性能的研究和开发。
详细内容:
标题:关于 o1-mini 在 2024 年美国邀请赛数学考试(AIME)中的表现讨论
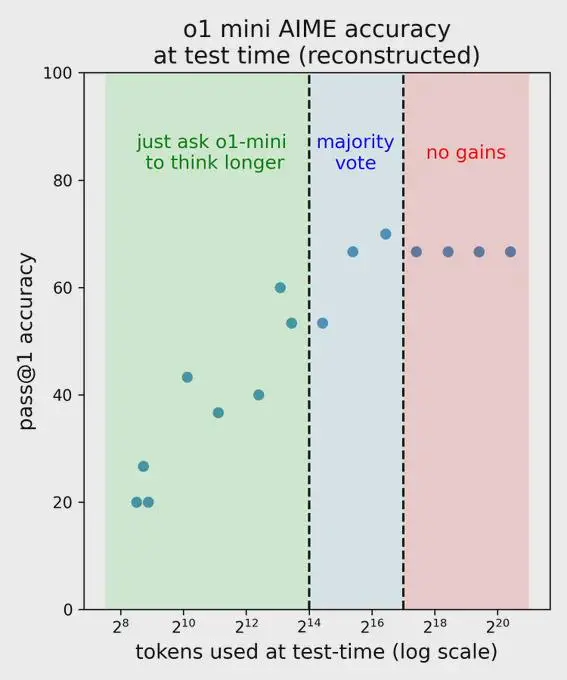
这篇在 Reddit 上引发热议的帖子,主要围绕一张展示 o1-mini 在不同策略下于 2024 年美国邀请赛数学考试(AIME)中表现的散点图展开。该帖子获得了众多关注,众多用户纷纷发表评论参与讨论。
帖子中的散点图呈现了不同测试时间下 AI 模型的准确率与使用的 token 数量之间的关系,包含了“just ask o1-mini to think longer”“majority vote”以及“no gains”三种策略。此图引发了关于 AI 模型性能优化策略等方面的深入探讨。
在讨论中,有人表示可以用类似的方法在本地模型如 Nemo 上获得相近但稍逊一筹的结果,并分享了相关系统提示。还有人指出在 optillm 中尝试不同技术时,随着时间推移会出现一些问题,且更多的 tokens 并非在所有基准测试中都能带来更好结果。
有人分享了对 Qwen 的观察,比如它常能给出相当不错的“部分得分”答案,也能正确回答不少问题,但错误往往源于早期的一些错误推理步骤。
有人提出如何对 LLMs 进行基准测试以及最简单的测试方法,还有人认为如果逻辑不是线性的,而是允许循环,效果可能会更好。
有人提供了背景信息,包括相关的 X 线程链接、测试的问题等。
关于 o1-mini 的讨论存在一些共识,大家普遍认为对于本地 LLM 用户来说,受限于 VRAM,如果能在减少 VRAM 的情况下让模型思考更久以获得相似质量的答案,将能获得更好的本地结果。但也有人认为当前开源环境中的相关系统还有待改进。
特别有见地的观点如,有人认为 o1-mini 的表现很有潜力,若能更好地复制类似系统,将为本地改进带来可能。
总之,这场关于 o1-mini 在 AIME 中表现的讨论,为 AI 模型的研究和发展提供了丰富的思路和方向。


感谢您的耐心阅读!来选个表情,或者留个评论吧!