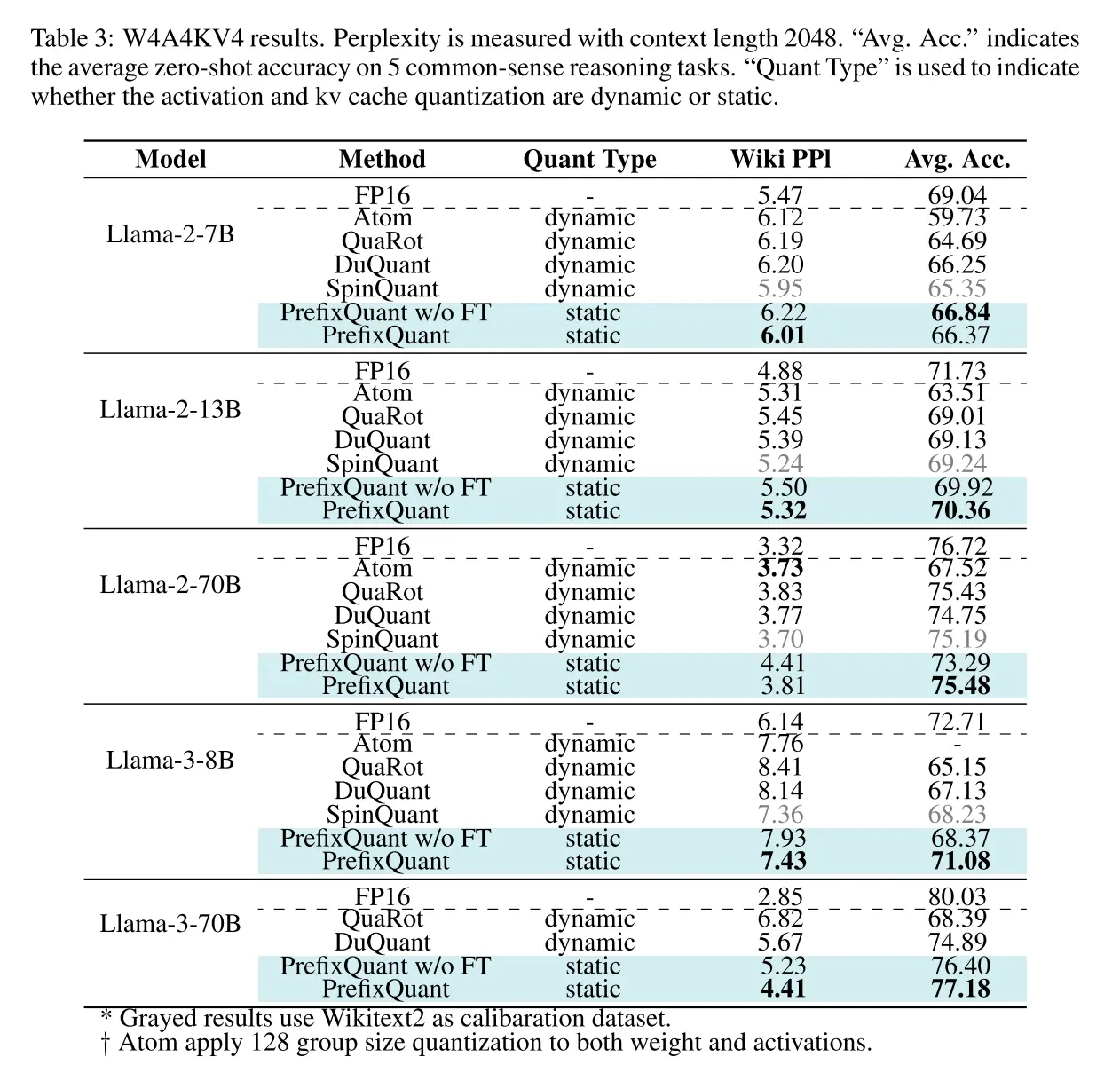
论文:https://arxiv.org/abs/2410.05265。代码:https://github.com/ChenMnZ/PrefixQuant。这是什么?这种量化方法允许你在W4A4KV4(4位权重、4位激活和4位键值缓存)中进行推理。此外,以前的方法依赖于昂贵的每个标记动态量化来处理不同标记内的幅度波动,而本文成功地消除了所有异常值,并促进了对激活和键值缓存的高效每个张量静态量化。一些实验结果如下:
讨论总结
这个讨论围绕PrefixQuant量化算法展开。大部分评论者对这个新算法表现出兴趣和积极态度,如感谢分享、认为算法有趣、期待社区关注或对测试表示期待。同时也有关于PrefixQuant与llama.cpp量化数据比较的深入讨论,涉及数据可比性、不同量化类型等多方面。还有评论者提出了关于模型内存节省量的疑问。
主要观点
- 👍 感谢分享量化算法相关内容。
- 支持理由:对新算法感兴趣并认可其价值。
- 反对声音:无。
- 🔥 认为新量化算法有趣。
- 正方观点:很多评论者觉得算法想法独特。
- 反方观点:无。
- 💡 对算法的良好效果表示惊讶。
- 解释:评论者觉得难以相信效果这么好。
- 💡 期待推理内核发布后进行测试。
- 解释:对算法感兴趣并希望深入测试。
- 💡 质疑对比数据时使用的wiki文本是否相同。
- 解释:在量化方法比较中对数据可比性提出质疑。
金句与有趣评论
- “😂 Thanks for sharing. This is such an interesting idea.”
- 亮点:表达对分享算法的感谢并认可算法有趣。
- “🤔 Inevitable-Start-653: Oowee extremally interesting!”
- 亮点:强烈表达对算法的兴趣。
- “👀 I’ll be interested to test once the inferencing kernels are released.”
- 亮点:体现对算法测试的期待。
- “🤔 Just to be sure, is it the same wiki text? Afaik there’s wiki 1 and 2, and sometimes when comparing perplexity online people don’t use the same source for wiki text, but a random link in some random GitHub account. It’s a mess.”
- 亮点:在数据比较时对关键因素提出疑问。
情感分析
总体情感倾向是积极的,大多数评论者对PrefixQuant算法表现出兴趣、期待或认可。主要分歧点在于PrefixQuant与llama.cpp量化数据比较方面,如数据是否可比等,原因是不同项目可能有不同的量化方式、使用的文件版本不同等多种复杂因素。
趋势与预测
- 新兴话题:关于模型内存节省量的进一步探讨。
- 潜在影响:如果PrefixQuant算法确实有效,可能会影响到相关模型量化方式的发展方向,也可能促使更多人对量化算法进行优化和改进。
详细内容:
标题:关于新型量化算法“PrefixQuant”在 Reddit 上的热门讨论
在 Reddit 上,一篇关于新型量化算法“PrefixQuant”的帖子引起了广泛关注。该帖子提供了相关论文和代码的链接,即https://arxiv.org/abs/2410.05265和https://github.com/ChenMnZ/PrefixQuant。帖子介绍了这一量化方法能在 W4A4KV4(4 位权重、4 位激活和 4 位 KV 缓存)下运行推理,还指出以往方法依靠代价高昂的每标记动态量化来处理不同标记内的幅度波动,而此论文成功消除了所有异常值,并为激活和 KV 缓存实现了高效的每张量静态量化。此帖获得了众多点赞和大量评论,引发了关于该算法多方面的热烈讨论。
讨论的焦点主要集中在对这一算法的不同见解和观点。有人表示:“这是个有趣的想法,真不敢相信效果这么好。等推理内核发布后,我会很有兴趣测试。”还有人说:“哇,太有趣了!期待能被社区采用。”
关于算法与其他相关成果的比较,也有诸多观点。有人提到“llama.cpp 报告了 wiki 文本上 q4_K_M 的 ppl 为 5.88”,并给出了相关链接https://github.com/ggerganov/llama.cpp/discussions/406#discussioncomment-7178025。随即有人回应“要确定是否是相同的 wiki 文本。据我所知有 wiki 1 和 2,有时在线比较困惑度时,人们在不同的随机 GitHub 账户中使用的不是相同的 wiki 文本来源,这很混乱。”
还有人指出:“OP 中的表格是对权重、激活和 KV 进行量化。不确定上述的基准测试是否完全具有可比性。”有人进一步补充:“是的,被比较的 llama.cpp 版本可能使用的是 fp16 KV,因为 llama.cpp 中启用量化 KV 缓存的功能相当新。”
对于模型的具体参数和效果,也有深入的探讨。有人提到“据我所知,对于 llama.cpp 假定是 Wiki Text 2,得分是针对L2 7B,还有一个得分板显示 L3 8B - q4_0 是 6.7 对比上述表格中的 7.43。从尺寸方面来看,q4_0 是 4.34GB,q4_K_M 是 4.58GB,q5_0 是 5.21GB。所以,我认为它更接近 q4_0。”
有人深入研究代码后指出:“大致上,对于模型的开头和结尾以及中间每隔三层,会触发更高精度(Q6)的情况。不能仅根据大小来比较位和量化方法,因为这需要很好地理解底层的容器格式和量化方法。”
有人认为:“绝对!我同意,这主要是为了解决关于量化更接近或更远离彼此的最初评论。我认为文件大小和 t/s 与论文中测量的困惑度一样,从最终用户的角度来看至关重要,我很想更多地了解这些与新方法的关系。”
此外,还有人询问:“这个模型节省了多少内存?”
总的来说,大家对这一新型量化算法表现出了浓厚的兴趣,讨论中既有对其创新性的肯定,也有在比较和应用方面的谨慎思考,同时还存在一些有待进一步明确和探讨的问题。这些讨论充分展示了社区对新技术的关注和深入研究的精神。


感谢您的耐心阅读!来选个表情,或者留个评论吧!