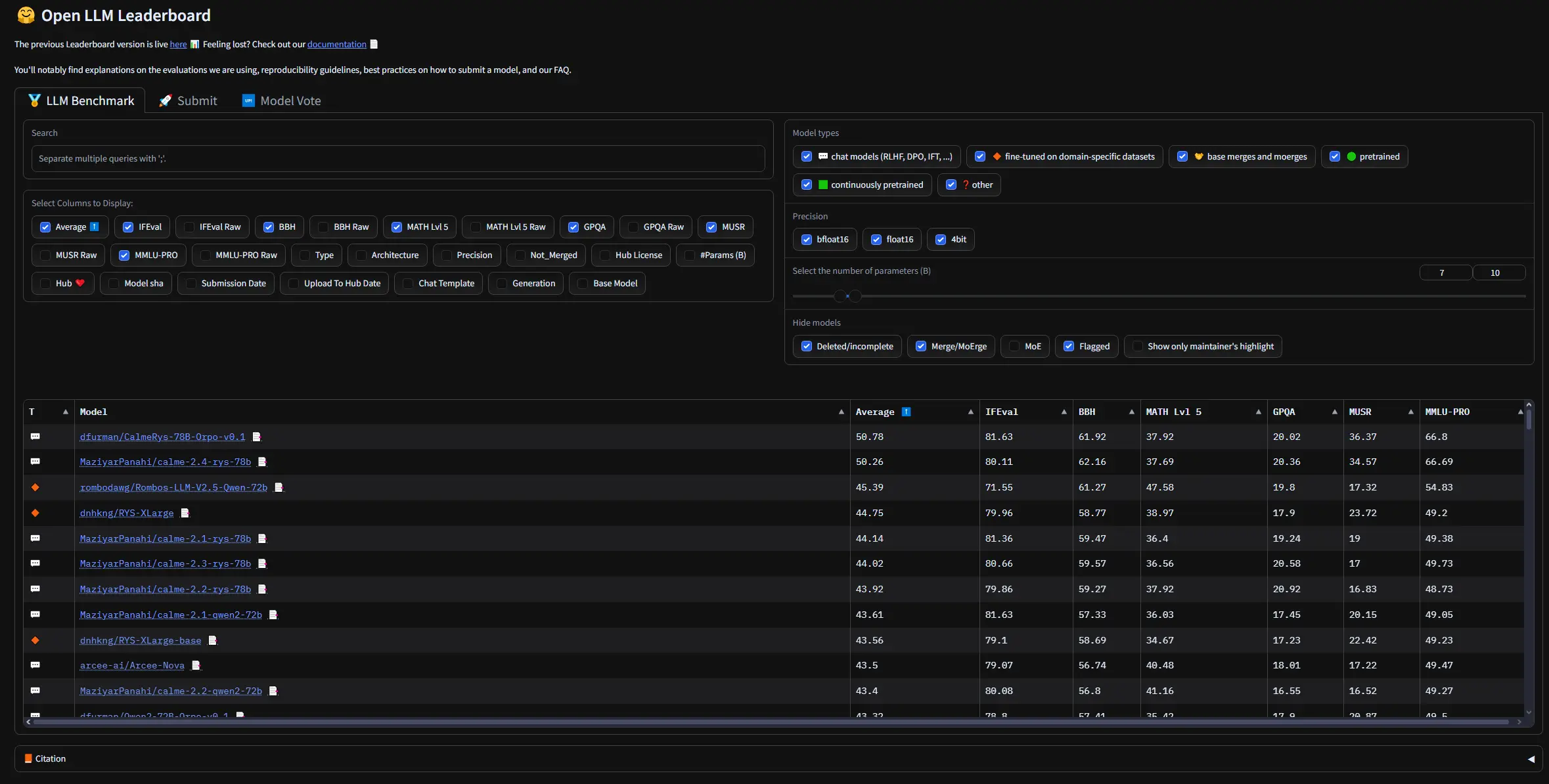
我一直向人和公司鼓吹遵循我的方法来提高他们的大型语言模型(LLM)质量,现在终于有成果证明我的努力了。我创建的持续微调方法(链接如下)通过结合新权重和之前的权重,在防止微调人工智能模型时产生的损失方面表现出色。[https://docs.google.com/document/d/1OjbjU5AOz4Ftn9xHQrX3oFQGhQ6RDUuXQipnQ9gn6tU/edit?usp=sharing]我强烈建议阅读我上面写的相关内容,它信息量很大,而且与一般的大型语言模型(LLM)论文相比篇幅很短。如你所见,我将该方法的最后一部分(合并)应用到所有Qwen - 2.5模型的权重上,创建了自己的Rombos - LLM - V2.5人工智能模型,并且它们在排行榜的每个类别中都名列前茅(或接近名列前茅)。
讨论总结
原帖作者介绍了自己的连续微调方法在提升语言模型(LLM)质量方面的有效性,并展示了应用该方法后的成果。评论者们提出了各种各样的问题,包括方法的具体步骤、对特定模型的应用、与其他方法的比较、硬件需求等,也有不少人对原帖作者表示感谢、认可和赞赏。整体氛围是积极的技术交流,大家都对这个连续微调方法表现出浓厚的兴趣。
主要观点
- 👍 原帖作者的连续微调方法如果可靠的话令人惊叹
- 支持理由:原帖作者将此方法应用于Qwen - 2.5模型创建了自己的模型且在排行榜表现优异。
- 反对声音:部分人对模型仅在数学等级5提高分数提出质疑。
- 🔥 原帖作者应撰写更详细文章阐述发现并邀请知名微调者验证方法
- 正方观点:如果一切顺利,这个方法可能会成为微调领域的新标杆。
- 反方观点:无(未发现明确反对观点)。
- 💡 原帖中的用词存在混淆情况,建议使用特定术语
- 解释:原帖作者在描述模型忘记先前训练信息时使用“loss”这个词会令人困惑,建议使用“catastrophic forgetting”代替。
- 💡 原帖内容具有发表文章的价值
- 解释:原帖作者介绍的方法及成果很有价值,值得写成研究文章或者在Medium上发表的文章。
- 💡 12GB VRAM对于8B模型遵循原方法是否有挑战存在不同看法
- 解释:有人认为有挑战,也有人认为12GB VRAM训练8B模型应该可行,但合并操作可能需要大内存。
金句与有趣评论
- “😂 非常有趣。纠正我如果我错了: - 步骤1:使用自定义数据集对基础模型(即qwen - base)进行指令微调以获得适配器 - 步骤2:将适配器应用于通用指令模型(qwen - instruct)之上以获得新模型(qwen - instruct - custom) - 步骤3:合并基础模型(qwen - base)、通用指令模型(qwen - instruct)和定制的通用指令模型(qwen - instruct - custom)。这对吗?这是一种可靠的添加领域知识的方法吗?”
- 亮点:清晰地总结并询问原帖作者连续微调方法的步骤,体现出对方法的好奇与探索。
- “🤔 嗯。你的方法很有趣,但我不那么乐观。就我所见,你的模型基本上提高了数学5级的分数。”
- 亮点:对原帖作者的方法成果提出质疑,是少数的不同声音。
- “👀 原帖作者:Prereqs? I guess python, git, mergekit. Not sure what else”
- 亮点:简洁回答关于阅读简介之前的先决条件的问题。
- “😂 I also have 12gb vram. Heres what you can do: Train 8b or 12b models on colab as qlora. You get up to 12h free each session. Chunk your training sets so it fits the time constraint. Upload to hf. Merge them with rombos method locally.”
- 亮点:分享12GB VRAM时在Colab训练、分块训练集、上传到hf再本地合并的操作,具有一定的实用性。
- “🤔 I have read your document and it was bit confusing that you use the word "loss" when the model forgets previous training information.”
- 亮点:指出原帖作者文档中的用词问题,有助于原帖内容的改进。
情感分析
总体情感倾向是积极的。大部分评论者对原帖作者表示感兴趣、感谢、认可和赞赏,主要分歧点在于对原帖作者成果的评估,如模型提升的程度等。可能的原因是不同评论者的知识背景、对模型的期望和评估标准不同。
趋势与预测
- 新兴话题:原帖作者是否会撰写学术论文并提交同行评审,以及连续微调方法在更多类型模型(如类似Qwen2 - VL训练方式的模型)上的应用效果。
- 潜在影响:如果该连续微调方法被更多人认可和采用,可能会对大型语言模型的微调领域产生积极影响,提高模型的性能和质量,推动相关技术的发展。
详细内容:
标题:Reddit 热议:创新的连续微调方法在 LLM 领域引发轰动
在 Reddit 上,一篇题为“Im pretty happy with How my method worked out (Continuous Finetuning) Topped Open-LLM-leaderboard with 72b”的帖子引起了广泛关注。该帖子获得了众多点赞和大量评论,主要介绍了一种创新的连续微调方法,用于提升语言模型(LLM)的质量。
帖子作者称其一直倡导人们和公司采用他的方法,如今终于有了成果证明。他创建的连续微调方法能够出色地防止因微调 AI 模型而导致的损失,通过结合新的和之前的权重。文中还提供了相关的文档链接https://docs.google.com/document/d/1OjbjU5AOz4Ftn9xHQrX3oFQGhQ6RDUuXQipnQ9gn6tU/edit?usp=sharing 。
在讨论中,主要观点如下: 有人认为基础模型学习效果更好,对指令模型进行微调可能是浪费时间。例如,有人分享道:“作为一名在相关领域探索的研究者,我发现基础模型在学习新知识方面具有更大的潜力。指令模型由于已经在特定指令集上进行了过度微调,再进行新的指令训练难度极大且效果不佳。从我自己的测试来看,这一观点确实成立。” 也有人对该方法的通用性表示好奇,询问是否适用于其他合并工具。比如,有人问道:“感谢您有趣且出色的工作。您认为这会适用于其他合并工具吗?” 还有人提出关于训练数据集的问题,以及在不同硬件条件下如何进行本地训练等。
讨论中存在一些共识,即大家普遍对这种创新方法表示关注,并期待其能为 LLM 的发展带来更多积极影响。
特别有见地的观点如有人提到“合并”类似于“git 合并”操作,对每个权重集进行“冲突解决”,以达到保留多个微调模型的大部分知识的目标。
然而,也有人对该方法持相对保守的态度。例如,有人表示:“您的方法很有趣,但我稍微没那么乐观。”
总之,这次关于连续微调方法的讨论展示了 Reddit 社区对 LLM 领域创新的积极参与和深入思考,为相关技术的发展提供了丰富的视角和可能性。


感谢您的耐心阅读!来选个表情,或者留个评论吧!