如果你使用Hugging Face库来微调你的大型语言模型(TRL和transformers),小批量大小和梯度累积的微调会严重表现不佳!
这里有一些关于Llama 3.2和SmolM - 135M的实验。
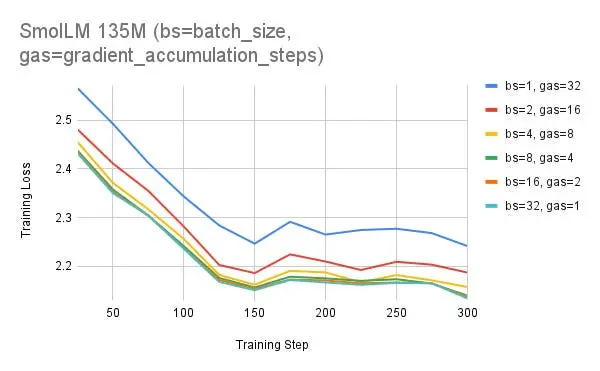
当batch_size = 1且gradient_accumulation_steps = 32时,比batch_size = 32且gradient_accumulation_steps = 1要差得多,尽管它们在数学上是等效的。
我也可以用Qwen2.5来证实这一点。模型参数的精度并不重要。在bf16和fp32权重下都会发生这种情况。我几天前在TRL库中开了一个问题,但从那以后没什么进展。
讨论总结
原帖指出在使用Hugging Face库(TRL和transformers)对LLM进行微调时,小批量尺寸和梯度累积会显著表现不佳,并给出了相关实验结果。评论者们从不同角度进行回应,有的表达感谢,因为原帖解答了自己在微调工作中的疑惑;有的对原帖中的数据和现象感兴趣,希望能听到更多解释;有的进行了自己的实验测试并提出疑问;还有的从技术角度探讨了梯度累积、批量大小等相关概念,整体氛围充满对这一现象的探索欲。
主要观点
- 👍 希望有一个关于如何实际微调现代模型的最新端到端指南
- 支持理由:很多人有相关知识基础但缺乏微调现代模型的最佳实践知识,而且存在很多不同的微调建议。
- 反对声音:无
- 🔥 原帖分享的内容有帮助
- 正方观点:原帖对使用特定库微调时小批量和梯度累积性能差的阐述对一些人的微调工作有指导意义。
- 反方观点:无
- 💡 理论上梯度累积不应有影响
- 正方观点:以nanoGPT为例无ac也能得到相同结果。
- 反方观点:有实验表明在特定库下小批量和梯度累积微调性能差。
- 🤔 改变梯度累积步长会改变总训练批量大小
- 解释:不同的梯度累积步长对应的学习曲线和训练步长效果不同。
- 👀 如果使用batch_size = 1时输入中不会有填充令牌,而更高的batch_size会使输入被填充
- 解释:这一现象与小批量和梯度累积性能差的情况可能存在关联。
金句与有趣评论
- “😂 我真的希望有一个关于如何实际微调现代模型的最新端到端指南。”
- 亮点:反映出很多人在微调现代模型时缺乏系统性的指导。
- “🤔 那很有趣。我一直认为当涉及到最终结果时它们是相等的,这就是它被“营销”的方式——最终结果质量的决定因素仅仅是你的全局批量大小,而不是微批量大小或梯度累积步骤。”
- 亮点:揭示了人们之前对批量大小和梯度累积等效性的固有认知。
- “👀 如果您使用Hugging Face库(TRL和transformers)来微调您的LLM,小批量大小和梯度累积的微调性能会显著不佳!”
- 亮点:原帖核心观点的精炼表达。
- “💡 在这种情况下,训练损失存在差异,但验证损失差异不大,所以也许模型本身没有太大差异?”
- 亮点:通过实验结果提出对模型差异的推测。
- “👍 Thanks for sharing this! Very helpful.”
- 亮点:简单直接地表达对原帖分享内容的认可。
情感分析
总体情感倾向是积极的。主要分歧点在于理论上梯度累积不应有影响,但原帖中的实验结果显示小批量和梯度累积在特定库下微调性能差。可能的原因是理论与实际应用场景存在差异,不同的模型和实验设置会导致不同的结果。
趋势与预测
- 新兴话题:对batch_size = 1时不同梯度累积步长情况的进一步探究,以及如何通过缩放处理相同样本数量。
- 潜在影响:如果相关问题得到解决,将有助于在显存有限的情况下更好地进行模型微调,提高模型微调的效率和效果,对使用Hugging Face库进行LLM微调的人群有很大帮助。
详细内容:
标题:关于使用 Transformers 进行微调时小批量和梯度积累的表现问题引发热议
在 Reddit 上,一则题为“Fine-tuning with small batch sizes and gradient accumulation poorly perform if you use Transformers (TRL)!”的帖子引起了广泛关注。该帖指出,使用 Hugging Face 库对 LLM(如 TRL 和 transformers)进行微调时,小批量和梯度积累的组合表现不佳。帖子中还展示了有关 Llama 3.2 和 SmolM-135M 的实验,并提到在 TRL repo 中开了相关问题但未得到有效解决。此帖获得了众多点赞和大量评论。
讨论的焦点主要集中在以下几个方面: 有人表示希望能有最新的关于如何微调现代模型的端到端指南,因为虽有相关经验,但不清楚当前最佳实践。有人推荐了相关论文和手册,如 https://arxiv.org/pdf/2408.13296 以及 https://github.com/huggingface/alignment-handbook 。 有人将帖子中的 Colab 移植到 Unsloth 进行测试,发现训练损失有差异,但验证损失差异不大。 有人认为定义通用的最佳实践很困难,因为它取决于很多因素,如模型、硬件、预算和数据集。 还有人分享个人经历,称之前的微调效果不好,看到这个帖子准备调整参数。
关于批量大小和梯度积累的关系,有人认为它们在技术上存在一定差异。有人好奇关闭“flash_attention_2”时情况是否相同,得到的结果是趋势不变。
也有人指出,使用批量大小为 1 时输入不会有填充令牌,而较大批量时输入会有填充,还探讨了不同设置下的学习曲线差异。
讨论中的共识是,微调模型的效果受到多种复杂因素的影响,没有一种通用的最佳实践能够适用于所有情况。
特别有见地的观点是,希望能有更明确和实用的微调指南,帮助大家更好地应对这些问题。同时,不同因素的相互作用使得确定最佳方案变得具有挑战性。
总的来说,这次关于使用 Transformers 进行微调的讨论揭示了其中的复杂性和不确定性,也为进一步探索和优化提供了思考方向。


感谢您的耐心阅读!来选个表情,或者留个评论吧!