讨论总结
该讨论围绕Llama - 3.1 - Nemotron - 70B - Instruct是否在MMLU Pro基准测试中打败GPT - 4o或Sonnet 3.5展开。评论者从不同角度进行探讨,包括模型的训练方式、在不同任务中的表现、与其他模型的比较、基准测试的可信度等多方面内容,整体呈现理性讨论的氛围。
主要观点
- 👍 对Llama - 3.1 - Nemotron - 70B - Instruct在MMLU Pro基准测试结果表示关注
- 支持理由:原帖主题围绕此展开,众多评论以此为出发点讨论。
- 反对声音:无。
- 🔥 MMLU是知识评估基准,被提及模型按竞技偏好训练未增加知识
- 正方观点:MMLU的定义和模型训练的目的及表现可证明。
- 反方观点:无。
- 💡 若Llama - 3.1 - Nemotron - 70B - Instruct真的在MMLU Pro基准测试中击败了其他产品会包含相关基准测试
- 支持理由:ThisWillPass等评论者指出英伟达最初遗漏相关内容可作为判断依据。
- 反对声音:无。
- 💡 对竞技场分数意义存在疑惑,不知是否人为抬高
- 支持理由:why06提出疑问,其他评论者的讨论围绕此展开。
- 反对声音:无。
- 💡 在redAppleCore的测试中Qwen表现远超Nemotron
- 支持理由:redAppleCore亲自测试得出结论。
- 反对声音:无。
金句与有趣评论
- “🤔 Isn’t MMLU a benchmark for knowledge evaluation?”
- 亮点:提出关于MMLU性质的基础疑问,引发后续关于模型知识评估方面的讨论。
- “👀 Inevitable - Start - 653: Reflection beats it….😬”
- 亮点:简洁地给出Reflection在比较中的优势结论,引起对模型竞争关系的思考。
- “😂 arm2armreddit: maybe it beats everything 🤔😂”
- 亮点:以幽默诙谐的方式推测405B未出现在排行榜的原因,为严肃的讨论增添轻松氛围。
- “💡 ThisWillPass: They would have included this benchmark, if they had beat it in the first place.”
- 亮点:从逻辑角度出发,提出对测试结果的一种判断依据。
- “🤔 NEEDMOREVRAM: Claude? Claude is a gimped piece of shit. Nemotron wipes its ass with Claude3 when it comes to professional writing.”
- 亮点:用比较直白、夸张的语言表达对两个模型在专业写作方面的看法。
情感分析
总体情感倾向为理性探讨,没有明显的一边倒倾向。主要分歧点在于对Llama - 3.1 - Nemotron - 70B - Instruct模型能力的判断,例如在与其他模型比较中的表现优劣。可能的原因是不同评论者基于不同的测试、使用经验或者对基准测试的理解有所不同。
趋势与预测
- 新兴话题:对模型进行微调是否能改善在特定任务中的表现(如创意写作中遵循语法指令等方面)。
- 潜在影响:如果对模型微调确实能有效改善表现,可能会促使更多开发者对现有模型进行优化,改变人工智能模型的竞争格局,同时也可能影响用户对不同模型的选择。
详细内容:
标题:关于 Llama-3.1-Nemotron-70B-Instruct 模型的热门讨论
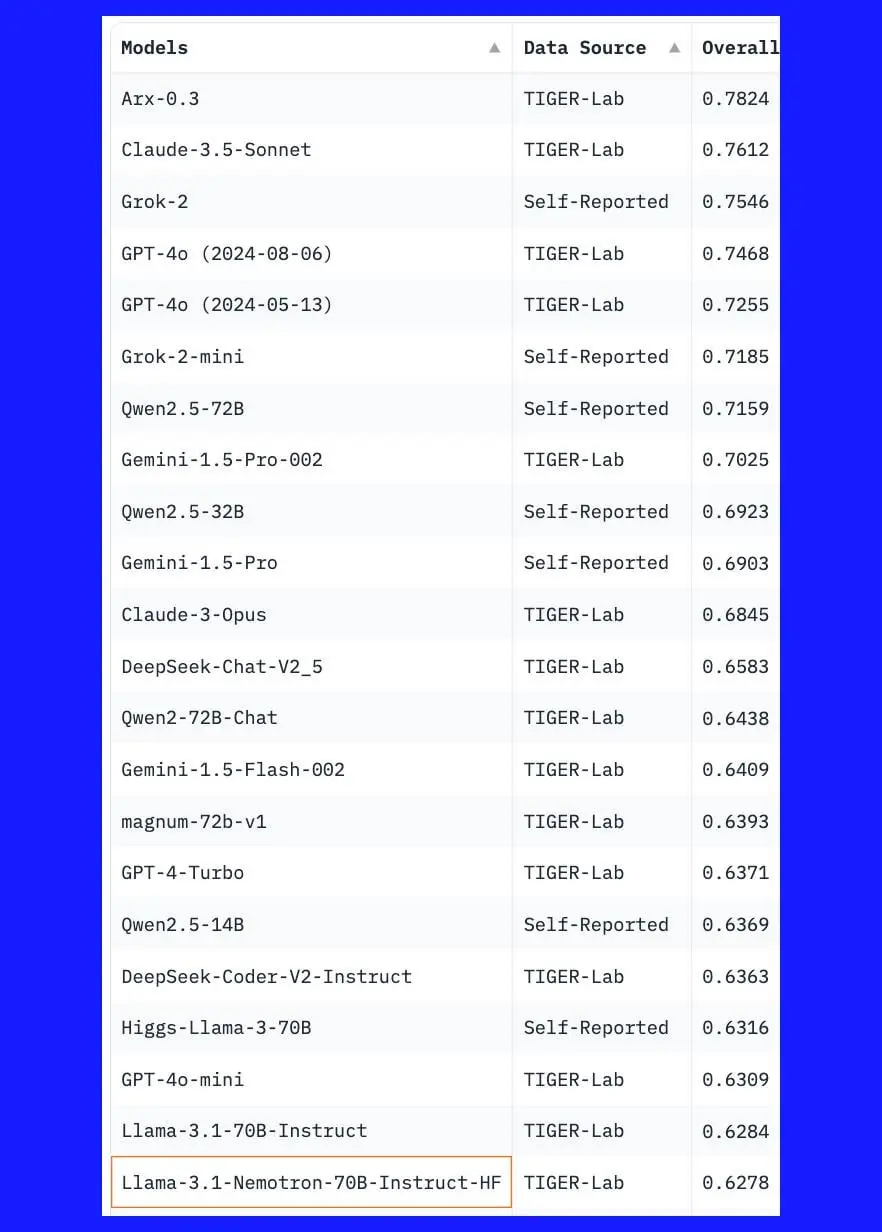
最近,Reddit 上关于 Llama-3.1-Nemotron-70B-Instruct 模型的讨论十分热烈。原帖https://huggingface.co/spaces/TIGER-Lab/MMLU-Pro指出该模型在 MMLU Pro 基准测试中的表现,并引发了众多网友的深入探讨。帖子获得了大量的关注,评论数众多。讨论的主要方向集中在该模型与其他模型的比较,以及其在不同基准测试中的表现。
讨论焦点与观点分析:
有人认为 Arx 是个骗局,此模型被训练用于在特定基准测试中取得好成绩。也有人分享了自己在 GitHub 页面创建问题的个人经历[https://github.com/TIGER-AI-Lab/MMLU-Pro/issues/31]。
有用户指出 Llama-3.1-Nemotron-70B-Instruct 只是按照人类偏好进行训练,在知识评估方面表现一般,生成的答案较为保守且简短。比如,有人分享道:“作为一名研究者,我注意到该模型在处理复杂问题时的能力有限,相比其他模型如 Mistral Large 有所不足。”
一些用户通过个人测试得出结论,如“在我的测试中,Qwen 表现更出色,Llama-3.1-Nemotron-70B-Instruct 令人失望。”
对于该模型在 Arena 基准测试中的表现,看法不一。有人认为 Arena 是基于人类偏好,有一定价值但也存在问题,比如“我仍然会时不时看看 Arena,但我更喜欢像 LiveBench 这样定期更新数据集的基准测试。”
还有人探讨了模型的优化和改进方法,比如“从我的理解来看,微调会有很大帮助。”
讨论中的共识在于大家都在关注模型的性能和实际应用效果,不同的观点和经历丰富了对该模型的认识。
总之,关于 Llama-3.1-Nemotron-70B-Instruct 模型的讨论展现了大家对人工智能模型的深入思考和探索,也反映了在评估模型性能方面的复杂性和多样性。


感谢您的耐心阅读!来选个表情,或者留个评论吧!