大家好,我们刚刚发布了SmolLM2,这是一个用于设备端应用的小型大语言模型(LLM)新系列。我们在SmolLM1的基础上进行了一些实质性的改进,特别是1.7B模型: - 更好的指令遵循,支持文本重写、摘要和函数调用 - 我们还改进了数学推理和知识。迫不及待地想看看你们用这些模型构建什么!你可以在这个集合中找到三种规模(1.7B、360M和135M):https://huggingface.co/collections/HuggingFaceTB/smollm2 - 6723884218bcda64b34d7db9。像往常一样,我们将在未来几周内发布完整的训练配方和数据集!
讨论总结
这个讨论围绕着新发布的SmolLM2模型展开。从模型的性能对比、资源分享,到具体应用场景如在电脑上运行的硬件需求,以及模型转换、预训练等技术方面都有涉及。大多数评论者对该模型持积极态度,部分也提出了一些疑问和建设性意见,整体氛围活跃且充满技术交流的氛围。
主要观点
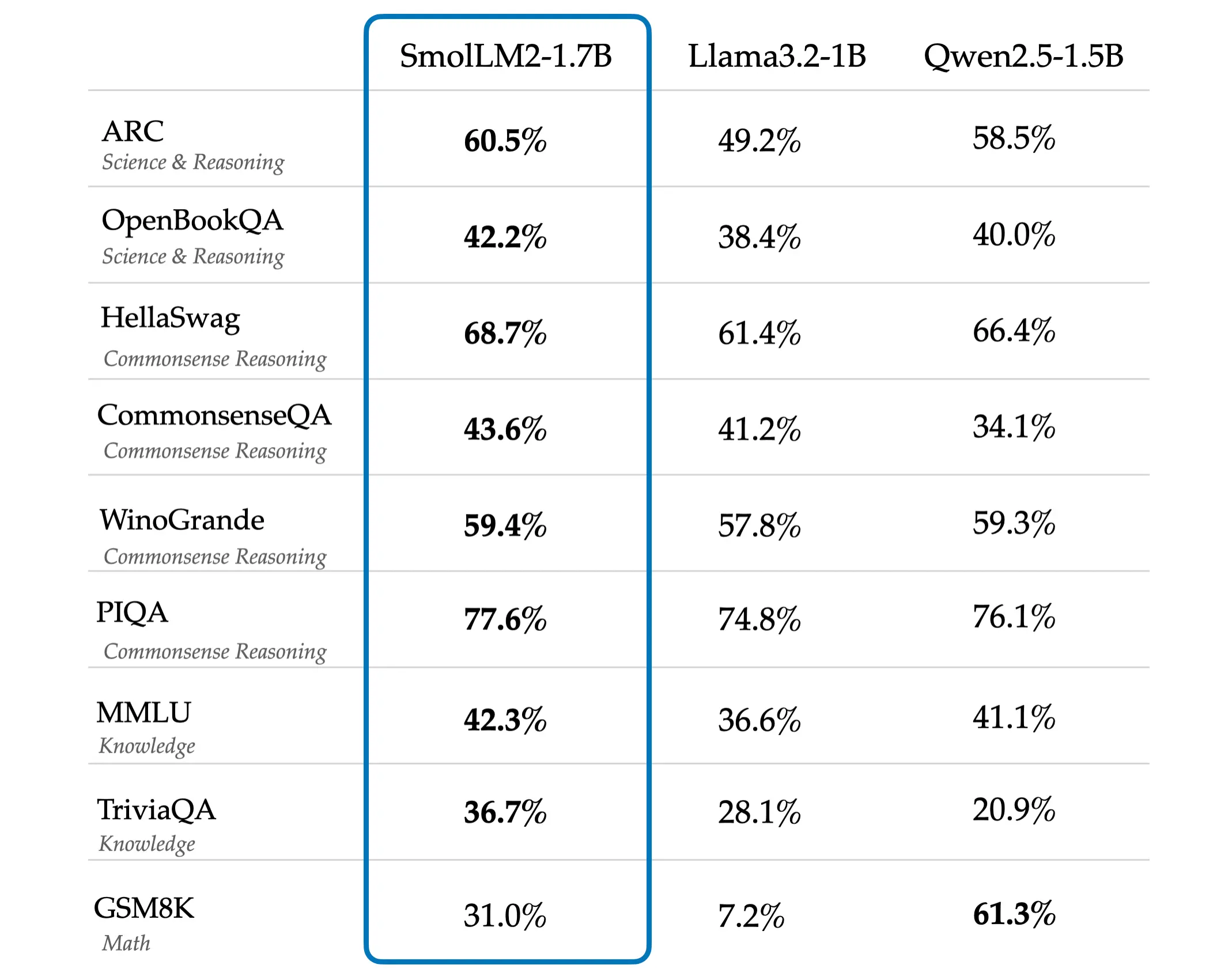
- 👍 SmolLM2可与Qwen 2.5进行基准对比且相当独特
- 支持理由:新的对比情况可作为新的基准,值得关注
- 反对声音:无
- 🔥 模型小,持续预训练/微调实用
- 正方观点:模型足够小使得操作具有实用性
- 反方观点:无
- 💡 1.7B模型对于其小体积而言表现惊人
- 解释:在小于2B的模型中可能是最好的,表现连贯且遵循指令良好
- 💡 对如何在电脑上运行SmolLM2存在疑问以及相应解答
- 解释:有人提问普通电脑是否能运行,也有人给出可行及运行条件和方式等解答
- 💡 建议将MiniCPM - 2B - dpo - bf16模型加入基准测试
- 解释:认为该模型强大,加入能更全面展示小模型性能
金句与有趣评论
- “😂 FrostyContribution35: Eyy a new llm that benchmarks against Qwen 2.5, nice”
- 亮点:简洁表达出对新模型能与Qwen 2.5对比的积极看法
- “🤔 这些模型似乎足够小,以使持续预训练/微调变得实用。”
- 亮点:点出模型小这一特性在预训练/微调方面的实用性
- “👀 GamingBread4: Even if you have extremely middling hardware. If you have a graphics card with like 4 - 8gb of VRAM, you can "fit" these smaller models into the VRAM.”
- 亮点:详细说明普通硬件运行模型所需显存等条件
情感分析
总体情感倾向是积极的。主要分歧点在于对模型的特别之处看法不同,如有的认为模型没有太多特别之处,而大多数人对模型发布、性能等持积极认可态度。可能的原因是不同评论者的技术背景和需求不同,导致对模型的评价有所差异。
趋势与预测
- 新兴话题:SmolLM2在专门的RAG任务上的适用性以及在ollama平台的可用性。
- 潜在影响:对小模型在更多应用场景的开发和优化有推动作用,也可能影响其他类似模型在技术发展和市场推广方面的策略。
详细内容:
《SmolLM2:小巧而强大的新模型引发Reddit热议》
在Reddit上,一则关于“SmolLM2: the new best small models for on-device applications”的帖子引发了广泛关注。此帖介绍了新发布的SmolLM2模型,并列举了其相对于SmolLM1的改进之处,还提供了模型的链接。该帖子获得了众多点赞和大量评论。
讨论焦点主要集中在以下几个方面:
- 与其他模型的对比:有人认为SmolLM2与Qwen2.5不相上下,也有人指出Qwen2.5的基准数据可能存在问题。
- 模型的实用性:有用户好奇普通消费者级别的电脑是否有足够能力实时运行,有人分享说即使硬件一般也能运行,还介绍了相关方法和程序。
- 模型的性能优势:不少人称赞1.7B模型表现出色,360M模型在尺寸、速度和质量上达到了很好的平衡,甚至能在旧的树莓派上舒适运行。
比如,有用户分享道:“作为一个相对新手的用户,在尝试运行模型时,发现即使自己的硬件条件一般,通过特定的程序和方法,也能成功运行这些较小的模型。”
对于模型与其他同类产品的比较,存在不同声音。有人觉得SmolLM2表现卓越,有人对Qwen2.5的评估方式提出质疑。
在模型的应用和优化方面,大家形成了一定共识,即这些小型模型为更多用户和开发者提供了便利和可能。
总的来说,SmolLM2的发布在Reddit上引起了热烈讨论,大家对其性能、应用和未来发展充满期待。


感谢您的耐心阅读!来选个表情,或者留个评论吧!