我在最近使用llama.cpp对英特尔Xe2 iGPU的测试中注意到的一件事是,理论上的最大半精度浮点运算(FP16)每秒万亿次浮点运算(TFLOPS)和内存带宽(MBW)只是情况的一部分。
我想分享这些数据,因为看到TFLOPS和MBW实际上只是等式的一部分是很有趣的,而且不同后端和设备之间的t/TFLOP效率和MBW效率有很大差异(CUDA后端似乎对安培(Ampere)和阿达(Ada)设备都最优化):
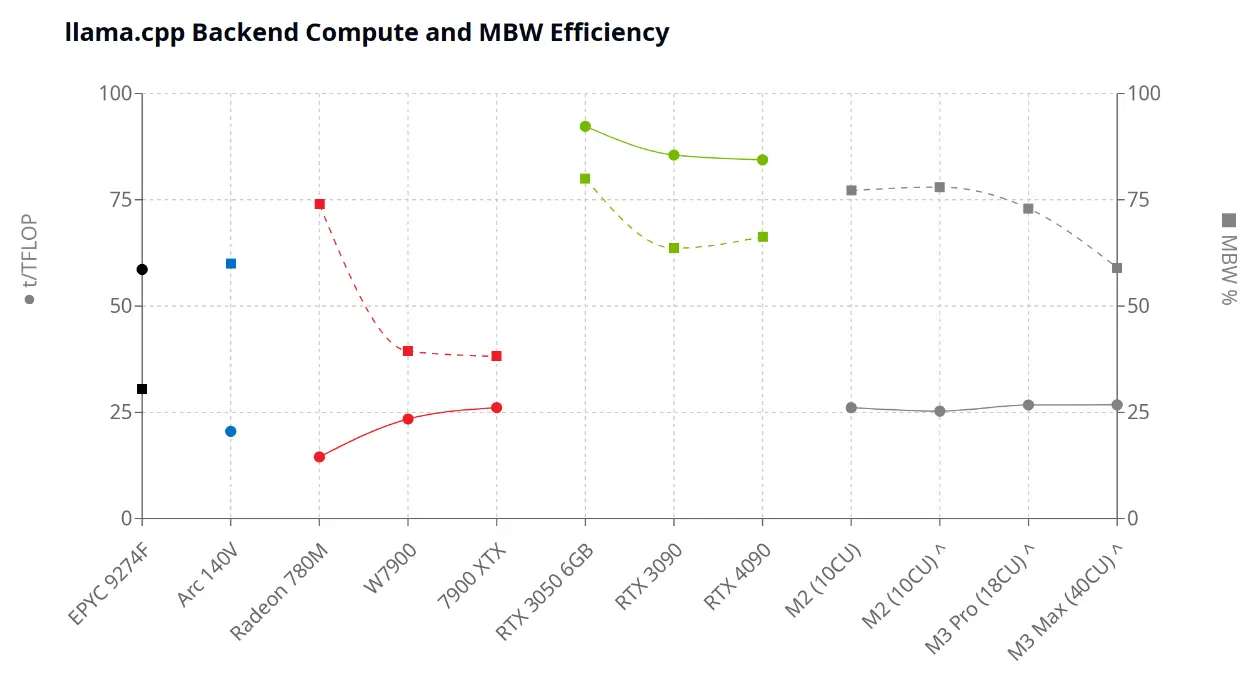
| 构建 | 硬件 | 后端 | FP16 TFLOPS | MBW GB/s | pp512 t/s | tg128 t/s | t/TFLOP | MBW % |
|---|---|---|---|---|---|---|---|---|
| b4008 | EPYC 9274F | CPU | 3.2 | 460.8 | 184.61 | 39.41 | 58.61 | 30.45 |
| b4008 | Arc 140V | IPEX - LLM | 32.0 | 136.5 | 656.5 | 22.98 | 20.52 | 59.93 |
| b4008 | Radeon 780M | ROCm | 16.6 | 89.6 | 240.79 | 18.61 | 14.51 | 73.94 |
| b4008 | W7900 | ROCm | 122.6 | 864 | 2872.74 | 95.56 | 23.43 | 39.37 |
| b4008 | 7900 XTX | ROCm | 122.8 | 960 | 3206.94 | 102.92 | 26.12 | 38.17 |
| b4008 | RTX 3050 6GB | CUDA (FA) | 13.6 | 168 | 1250.59 | 37.77 | 92.29 | 80.04 |
| b4011 | RTX 3090 | CUDA (FA) | 71.0 | 936.2 | 6073.39 | 167.28 | 85.54 | 63.61 |
| b4011 | RTX 4090 | CUDA (FA) | 165.2 | 1008 | 13944.43 | 187.7 | 84.41 | 66.29 |
| b4011 | M2 (10CU) | Metal | 7.1 | 100 | 185.34 | 21.67 | 26.10 | 77.15 |
| ??? | M2 (10CU) ^ | Metal | 7.1 | 100 | 179.57 | 21.91 | 25.29 | 78.00 |
| ??? | M3 Pro (18CU) ^ | Metal | 12.8 | 150 | 341.67 | 30.74 | 26.73 | 72.96 |
| ??? | M3 Max (40CU) ^ | Metal | 28.4 | 400 | 759.7 | 66.31 | 26.75 | 59.02 |
- ^ M3 Metal的数据来自llama.cpp苹果硅性能官方讨论线程,M2 10 CU的结果与我的M2 MBA结果非常匹配,所以我认为它们是最新的。
- 其余数字来自我在各种Linux系统(Arch、CachyOS、Ubuntu 24.04 TLS)上使用非常新的llama.cpp构建版本(b4008 - 4011)进行的测试。
- 所有测试都是使用[https://huggingface.co/TheBloke/Llama - 2 - 7B - GGUF](https://huggingface.co/TheBloke/Llama - 2 - 7B - GGUF)的Q4_0量化进行的。
- pp/tg数字是由llama - bench生成的,通常没有额外选项。对于英伟达显卡,CUDA运行使用 - fa 1(这会有不错的提升)。
- 虽然最大理论MBW相当直接,但最大(张量FP16)TFLOPS可能更棘手(取决于实际时钟速度,所以它们应该更多地被视为一个大致数字) - 值得注意的是,一些列表,如TechPowerUp的TFLOPS数字可能非常具有误导性,因为它们没有正确考虑像张量核心或XMX等张量/向量引擎(而且CPU取决于向量支持,也不那么直接 - 这是一个[使用o1 - preview来检查我的3050和EPYC TFLOPS估计值的示例](https://chatgpt.com/share/6726210e - 1100 - 8012 - 8953 - bedb79f9211b))。
一个有趣的事情是看到CUDA后端在令牌/FP16 TFLOP方面的效率 - 这适用于安培(3代)和阿达(4代)张量核心。我很确定我在这里的计算是正确的,我认为CUDA实现就是这么好。
无论如何,我想开启一个线程供以后参考,并且如果有人想要为他们特定的设置提供数据。你可以直接在这个线程发帖,也许这会是一个有趣/有用的资源。建议:
- 包含llama.cpp构建编号(使用单调数字,sha1更难追踪)
- 使用相同的GGUF以便于比较(推荐Q4_0,因为每个后端都支持)
- t/TFLOPS就是(pp512 / TFLOPS)
- MBW %是
100 * tg128 / (MBW/3.56)(llama2 q4_0是3.56GB)
更新:我让Claude[制作了一个可视化](https://claude.site/artifacts/f111e143 - f9a0 - 44b2 - ae37 - e2457b27e525),给后端着色,也许能更好地说明不同硬件/后端在计算和内存带宽效率方面的比较情况:
讨论总结
原帖分享了llama.cpp在不同设备/后端的计算和内存带宽效率相关的数据,还提供了可视化图表。评论者们在技术层面进行了多方面的交流,包括补充数据、探讨特定硬件(如Epyc、RTX系列、AMD系列等)的性能表现、提出对技术指标含义的疑问、分析运算方式以及比较不同后端等,整体氛围专注于技术探讨。
主要观点
- 👍 提供特定硬件相关的测试数据
- 支持理由:补充原帖数据,有助于更全面了解硬件性能,如fairydreaming提供llama.cpp b4011、1 x Epyc 9374F的测试数据,easyfab给出ARC 770不同后端的数据。
- 反对声音:无。
- 🔥 指出特定硬件性能的异常情况
- 正方观点:如s101c指出RTX 3050有最高的token/TFLOP比率很显著,在RTX 3060 12GB上有类似经验,性能超出应有水平。
- 反方观点:无。
- 💡 对硬件性能差异的原因进行猜测
- 对小模型MBW利用率低的现象,Calcidiol猜测与内存通道交错步长有关,SiEgE - F1认为是随机访问问题。
- 💡 提出对原帖技术相关的疑问
- 有评论者希望深入理解指标含义,还对英特尔、AMD、英伟达测试是否都在Linux下运行等多个技术问题进行提问。
- 💡 指出原帖数据或图表存在的问题
- 如有人指出原帖中Nvidia卡的FP16 TFLOPS数据存在错误,也有人认为原帖中的图表x轴点间插值无意义。
金句与有趣评论
- “😂 Everlier: OP, your posts are a delight. Thank you!”
- 亮点:简洁地表达对原帖的喜爱和感谢,侧面反映原帖价值。
- “🤔 It’s remarkable that RTX 3050 has the highest token/TFLOP ratio in this list.”
- 亮点:强调了RTX 3050在token/TFLOP比率方面的突出表现。
- “👀 Calcidiol: Per. what you mentioned about small model poor MBW my naive first guess is that if one has NN CPU cores all active and operating on say 12 memory channels then there might be a consideration having to do with the interleaving stride of N MBy (or whatever it is) per memory channel being too large possibly resulting in significant layer content of the 8 - 16 GBy or whatever of model data being actually stored in a couple/few memory channels vs. spread uniformly over the 12 available.”
- 亮点:对小模型MBW利用率低提出较为详细的初步猜测。
- “😉 Ok_Warning2146: 你的Nvidia卡的FP16 TFLOPS是错误的。”
- 亮点:直接指出原帖数据错误,吸引注意。
- “🤓 Philix: Taking a close look at the differences between pp512(prompt eval) and tg128(token generation) on the various bits of hardware leads to a pretty good explanation of why the performance differences are occurring.”
- 亮点:解释了通过观察特定指标差异可解释性能差异的原因。
情感分析
总体情感倾向为中性,主要是在技术层面进行探讨交流。分歧点在于对硬件性能的解读以及原帖数据的准确性。可能的原因是不同评论者从不同角度(如不同硬件的使用者、不同技术背景等)对原帖内容进行分析和理解。
趋势与预测
- 新兴话题:对CUDA内核和llama.cpp实现方式的深入探究(因为有评论者承认对此了解不足且可能存在运算方式的疑问)。
- 潜在影响:有助于优化llama.cpp在不同硬件上的性能表现,推动相关硬件在执行类似任务时的性能优化,为开发者和使用者在硬件选型及软件优化方面提供更多参考依据。
详细内容:
《探究 llama.cpp 在不同设备和后端的计算与内存带宽效率》
近日,Reddit 上一篇关于 llama.cpp 在不同设备和后端的性能测试的帖子引发了热烈讨论。该帖https://www.reddit.com/r/LocalLLaMA/comments/1gheslj/testing_llamacpp_with_intels_xe2_igpu_core_ultra/详细列举了不同硬件和后端下的性能数据,获得了众多关注,评论数众多。
帖子主要探讨了在不同设备和后端下,llama.cpp 的计算效率和内存带宽利用率的差异。其中包括 EPYC 9274F、Arc 140V、Radeon 780M 等硬件设备,以及 CPU、CUDA、ROCm 等后端。
讨论的焦点主要集中在以下几个方面: 有人指出 CUDA 后端在 Ampere 和 Ada 张量核心上的效率表现出色。例如,有人分享道:“RTX 3050 有着此列表中最高的 token/TFLOP 比率,我在 RTX 3060 12GB 上也有类似体验,在某种程度上,GPU 的表现超出了其规格。” 对于某些设备的低内存带宽利用率问题,有人认为这可能是随机访问问题,较小的模型权重放置在大的线性块中,导致更多的随机读写。 还有关于不同后端如 IPEX 和 SYCL 的性能比较和优化讨论。
在争议点方面,对于 AMD 和 Nvidia 显卡的性能差异存在不同看法。有人感叹:“哇,那些 RTX 3090 与 7900 XTX 的数字对比令人尴尬。7900 XTX 新了两年,理论上有更高的 TFLOPS 和内存带宽,但实际吞吐量却不如 RTX 3090,并认为 AMD 的软件支持有待改进。” 而共识在于大家都对硬件性能和优化表现出了浓厚兴趣,希望能找到更优的配置和解决方案。
特别有见地的观点如有人通过实验得出,LLM 推理在 Epyc Genoa 上的最佳核心数为 32 - 48 个,使用更多核心会导致性能下降。
总之,这次的讨论为大家深入了解 llama.cpp 在不同硬件和后端下的性能表现提供了丰富的视角和有价值的信息。


感谢您的耐心阅读!来选个表情,或者留个评论吧!