几天前我看到了有关最优功耗配置的帖子,于是决定深入研究,以下是我的发现:
测试设置:
我的双3090 Turbo显卡,每张卡运行在PCIE4.0x8,在Ollama上运行Qwen 32b,6_K_L,32k上下文。在优化设置下,调整功耗以及核心/显存偏移量,以查看如何高效推动这些GPU实现最大输出。
测试使用自定义脚本进行,运行了2000多次测试(约20小时),主要聚焦于寻找性能和效率之间的最佳平衡点,并且我监测了功耗、温度和处理吞吐量等参数。
脚本最初进行广泛扫描以找到最佳的宽泛配置,然后进行精细测试以发现最佳的整体配置。每个测试配置执行两次然后取平均值以减少差异。
在得出结果之前,我怀疑脚本或者我的测试方法在显存配置上出错了,但我仍会继续进一步测试,因为较低的显存时钟频率的表现并不像我认为的那样。我可能会在解决可能的显存偏移问题或者发现为什么较慢的显存时钟频率能产生更好的数据后重新运行测试。
我会在某个时候发布脚本,但我还需要对其进行更多修改。
起始广泛扫描配置:(起始值,结束值,步长) 初始功耗 = (100, 350, 50) 初始核心 = (1000, 2000, 200) 初始显存 = (1000, 10000, 1000)
关键发现:
分析数据后,简要情况如下:
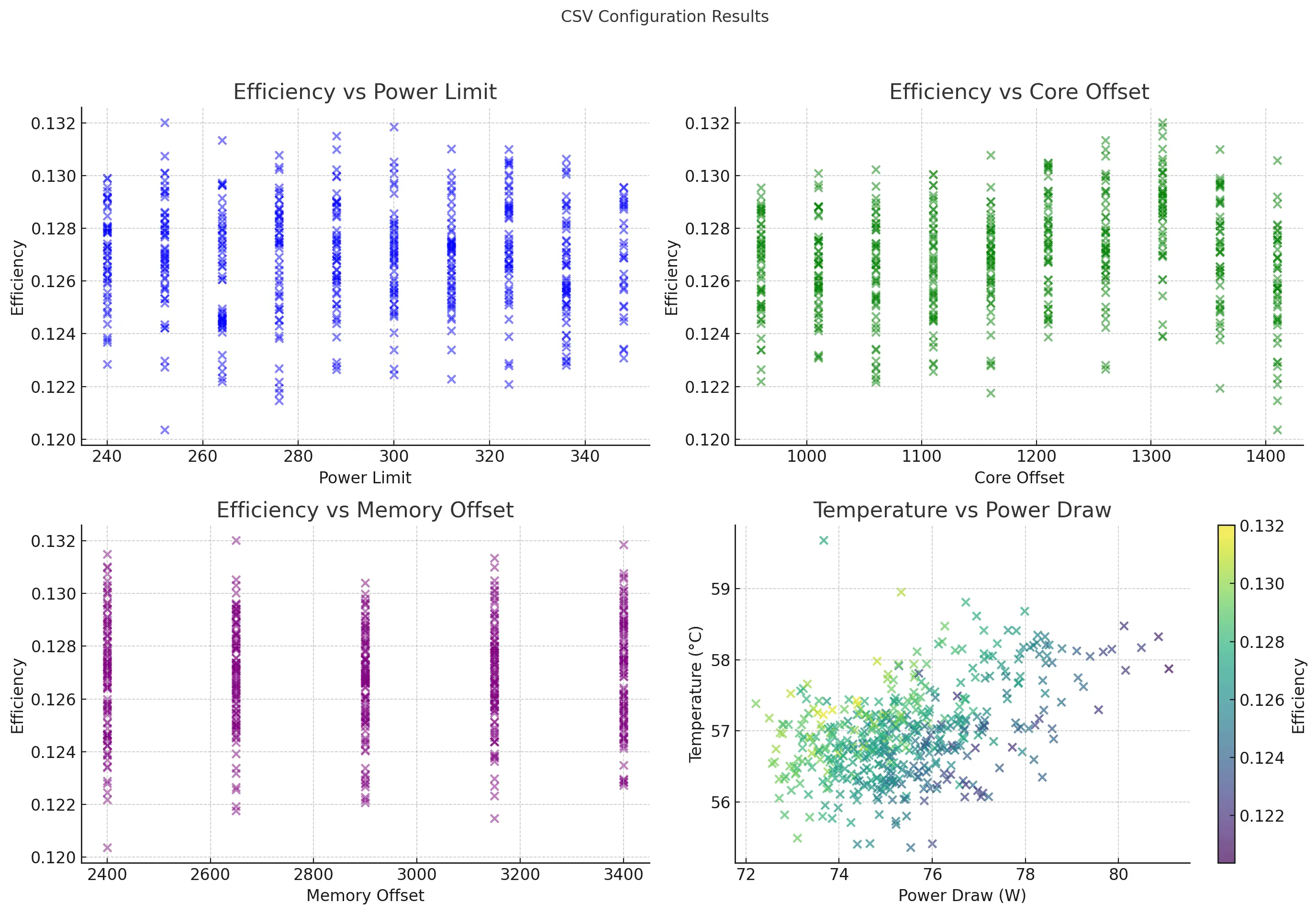
- 最有效配置:此设置每张卡功耗约74W(从nvidia - smi获取),温度保持在57°C左右,达到稳定的9.82个令牌/秒(这是基于输入和输出时间,而不仅仅是输出时间,所以到第一个令牌的时间也计入整体效率计算)。
- 功耗限制:252W
- 核心时钟:1310MHz
- 显存时钟:2650MHz
- 效率:0.132(最佳达成值)
- 效率与功耗设置:
- 一般在中等功耗限制范围(240 - 260W)以及适度的核心/显存偏移量下能获得更高效率。
- 不同配置下功耗和温度相对稳定,但过度提高显存偏移量不会产生太多额外效率,只会增加热量。
- 绘图可视化:
- 散点图展示了效率与功耗限制/核心偏移量/显存偏移量以及温度与功耗(以效率为颜色编码)。结果清晰地显示了哪些配置达到了最佳点。
太长不看版:
使用Ollama和2个3090显卡,我发现将功耗调整到252W、核心1310、显存2650时,在不使温度过高的情况下达到了效率和性能的最佳平衡。
记住芯片的个体差异,你的显卡在这些结果上可能更好或更差。
讨论总结
原帖作者对双3090显卡进行最优功率配置测试,通过大量测试得出最佳效率的配置参数,并以散点图展示相关数据。评论者从多方面进行讨论,有质疑原帖测试完整性的,如缺乏与TabbyAPI的比较;有对原帖使用软件及测试结果提出质疑的;也有对原帖成果表示肯定并期待针对其他场景进行测试的;还有受原帖启发打算进行相关延伸探索的,整体氛围围绕技术讨论且较为理性。
主要观点
- 👍 原帖对3090显卡进行功率配置测试并得出最佳效率配置参数
- 支持理由:进行了约2000次测试,给出了包括功率、核心、内存等方面的最佳配置数据。
- 反对声音:有评论者质疑其使用的软件及测试结果中的令牌生成速度。
- 🔥 原帖研究缺乏特定比较不够完整
- 正方观点:没有与TabbyAPI中类似EXL2量化加载以及推测解码比较,不够全面。
- 反方观点:无(未发现明确反对声音)。
- 💡 对原帖成果表示肯定并期待针对其他场景进行测试
- 解释:认可原帖测试成果,希望针对如图像生成或识别等不同场景进行类似测试。
- 💡 受原帖启发打算进行相关延伸探索(探究vcore能降低到何种程度)
- 解释:原帖对功率等配置的测试优化,启发评论者进一步探索核心电压方面的优化可能性。
- 💡 原帖研究中的令牌生成速度不可接受
- 解释:评论者以自己设备的运行速度对比,认为原帖中双3090运行32b模型每秒10个令牌的速度太低。
金句与有趣评论
- “🤔 It is interesting research, but it feels not complete without comparison with similar EXL2 quant loaded in TabbyAPI with speculative decoding.”
- 亮点:指出原帖研究在对比方面的不足,引发对研究完整性的思考。
- “👀 I get 50T/s on 32b (q4) with a 3090 + 3080Ti.”
- 亮点:通过自身设备的高性能数据,对比凸显原帖中令牌生成速度的低水平。
- “👍 talk_nerdy_to_m3:Wow, that’s pretty cool. Can you perform similar tests for different use cases? Image generation or recognition etc?”
- 亮点:对原帖成果表示肯定并提出新的测试期待。
- “💡 Now I gotta figure out how low I can drop vcore.”
- 亮点:体现出原帖对评论者的启发,有延伸探索的想法。
- “🙏 Thanks for posting initial finds, and thanks for your willingness to share the code to run these tests.”
- 亮点:表达对原帖作者的感谢,态度积极正面。
情感分析
总体情感倾向为中性偏积极。主要分歧点在于对原帖测试的认可度,部分评论者认为原帖存在不足如缺乏对比、测试结果不佳,而另一部分则对原帖表示肯定和感谢。可能的原因是不同评论者的技术背景和关注点不同,有些从更全面的研究角度看待,有些则更关注成果的积极面或者受到成果启发。
趋势与预测
- 新兴话题:针对不同使用场景(如图像生成等)进行类似功率配置测试可能会成为后续讨论的话题。
- 潜在影响:如果按照评论中的建议进行更多场景和更全面的测试,将有助于更深入地了解3090显卡在不同应用场景下的性能优化,为相关使用者(如工程师、研究人员、游戏玩家等)提供更有价值的参考。
详细内容:
标题:探索 3090s 最佳功率配置的热门讨论
最近,Reddit 上有一篇关于探索 3090s 最佳功率配置的帖子引起了众多网友的关注。该帖子详细介绍了作者的测试过程和关键发现,获得了大量的点赞和众多评论。
帖子中,作者使用双 3090s Turbos 进行了一系列测试,旨在找到性能和效率之间的最佳平衡点。测试包括优化功率、核心和内存偏移等设置,并通过运行 2000 多次测试(约 20 小时),监测功率消耗、温度和处理吞吐量等参数。
讨论焦点与观点分析:
有人认为这样的研究很有趣,但觉得如果能与类似的 EXL2 量化加载在 TabbyAPI 中的推测解码进行比较会更完整。有人分享了如何让草案模型与 Tabby 配合使用的方法和相关链接。
也有人询问是否有计划发布代码库或脚本以便大家调整自己的显卡,作者表示需要解决一些 bug 并添加更多功能,确保安全性。
还有人对测试结果提出质疑,认为与其他配置相比效率过低,应该考虑使用其他软件或测量完成特定提示所消耗的焦耳来确定效率。
有人则建议针对不同的用例,如图像生成或识别等进行类似测试。
同时,有人关心对于拥有 48GB VRAM 的构建,哪种模型效果最佳以及是否有大小限制。
共识方面,大家都对作者的研究和愿意分享的态度表示赞赏。
总之,这次关于 3090s 最佳功率配置的讨论为相关领域的爱好者和从业者提供了有价值的参考和思考方向。


感谢您的耐心阅读!来选个表情,或者留个评论吧!