嗨,大家好!我们最近制作了一个设备端小语言模型(SLM)排行榜,为本地语言模型爱好者提供资源。该排行榜旨在根据质量(使用ifEval)和性能指标(如响应时间、输出速度、预填充速度和功耗)更轻松地比较模型的量化版本。你可以在这里查看:
讨论总结
这是一个关于本地小语言模型(SLM)排行榜的讨论。帖子作者介绍了自己构建的排行榜及其功能,包括可以基于多种性能指标对比不同模型的量化版本。评论者们积极参与讨论,有推荐可加入排行榜的模型,探讨了衡量模型应有的指标(如设备、推理栈等),比较了不同模型在不同设备上的性能,整体氛围比较积极,大家都希望这个排行榜能更加完善和实用。
主要观点
- 👍 应增加更多模型到排行榜
- 支持理由:如Mandelaa提到了Danube 3、Danube 2等模型值得加入排行榜。
- 反对声音:无。
- 🔥 指标应展示更多内容
- 正方观点:Vegetable_Sun_9225认为指标应展示用于基准测试的设备、推理栈和构建日期等内容。
- 反方观点:无。
- 💡 存在比gemma 2 9b表现更好的小模型
- 解释:Feztopia指出有模型在自己的安卓设备上比gemma 2 9b表现好,速度更快。
- 💡 仅以内存衡量模型性能不够准确
- 解释:有评论者以自身设备OPI5 +为例,虽有高内存但受CPU限制运行模型很慢,所以认为应综合更多因素。
- 👍 认可排行榜的价值
- 支持理由:如评论者以自身使用体验证实Gemma质量较高,并感谢排行榜创建者。
金句与有趣评论
- “😂 Mandelaa: Next models: Mandelaa: Danube 3, Mandelaa: Danube 2 Mandelaa: SmolLM2 Mandelaa: Gemmasutra Mini (NSFW)”
- 亮点:直接给出了可添加到排行榜的模型名称,简单明了。
- “🤔 Metrics should show device used to benchmark, inference stack and the inference stack (build date).”
- 亮点:提出了指标应包含的新内容,对完善排行榜指标有建设性意义。
- “👀 Feztopia:There are smaller models outperforming gemma 2 9b, also that one is super slow on my android, I don’t know about iOS.”
- 亮点:比较了不同模型在安卓设备上的性能,引出设备差异对模型性能影响的思考。
情感分析
总体情感倾向是积极的。主要分歧点较少,大多数评论者认可排行榜的价值,少数评论者在对模型性能衡量指标上提出了一些不同的看法,如是否应加入更多衡量指标内容、以内存衡量模型性能是否准确等。可能的原因是大家都关注本地小语言模型的发展,并且希望排行榜能够更完善准确地反映模型性能。
趋势与预测
- 新兴话题:增加SBCs的基准测试可能会成为后续讨论的新话题。
- 潜在影响:对本地小语言模型在不同设备上的性能优化有积极的推动作用,也有助于开发者和使用者选择更合适的模型。
详细内容:
《关于On-Device小型语言模型排行榜的热门讨论》
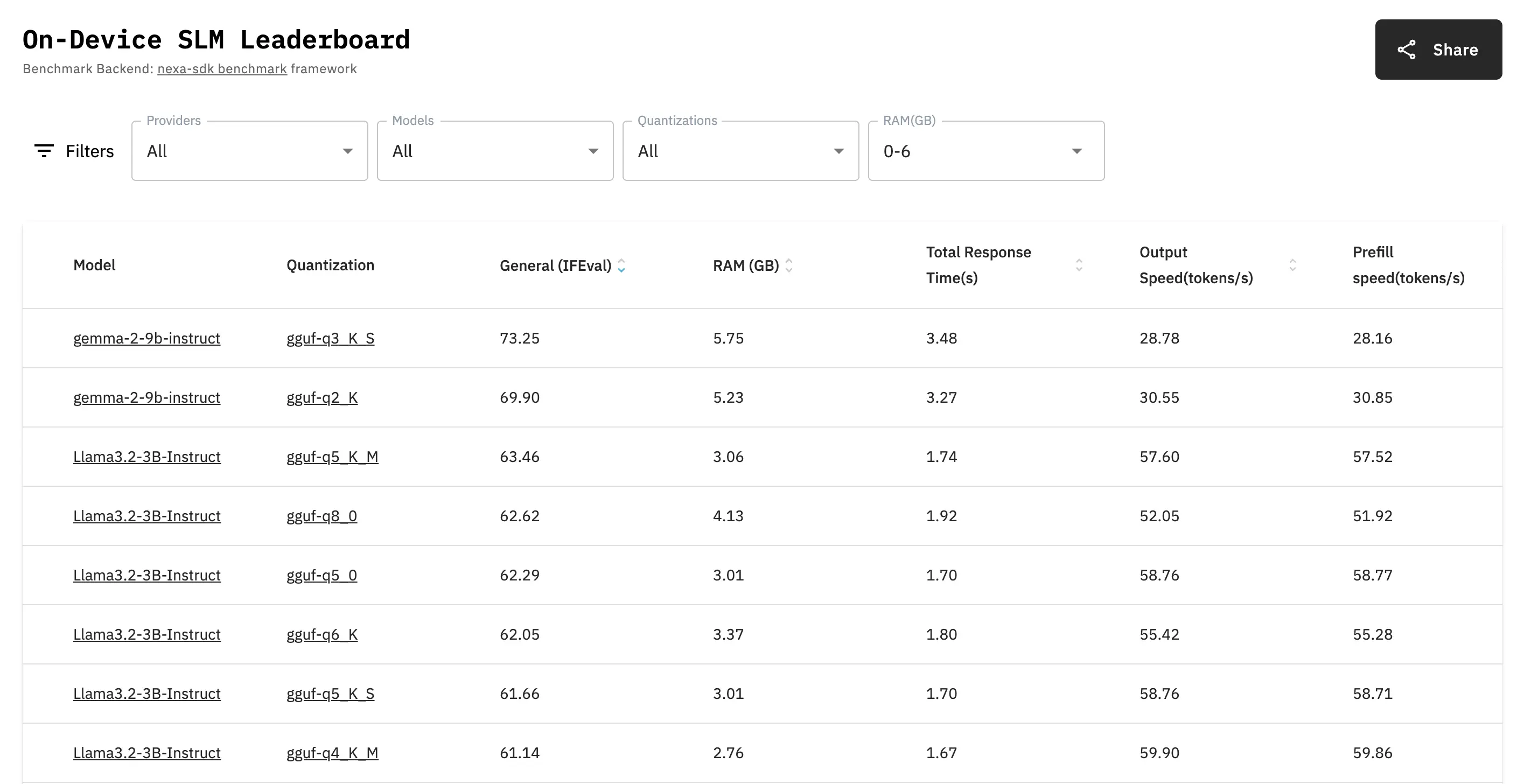
最近,在Reddit上有个热度颇高的帖子,创建者分享了一个On-Device小型语言模型(SLM)的排行榜[nexa.ai/leaderboard]。此排行榜旨在方便大家对比模型量化版本在质量(使用ifEval)和性能指标(如响应时间、输出速度、预填充速度和功耗)方面的表现,获得了众多关注,点赞数和评论数众多。
帖子中提到,目前排行榜包含了Llama3.2、Qwen2.5、Phi-3.5等多种模型。比如,对于iPhone 15且拥有6GB内存的设备,gemma-2-9b-instruct Q3_K_S是个不错的选择;若更看重响应速度,Llama3.2-3B Q5_K_M能将总响应时间减半,提升用户体验。
讨论焦点主要集中在几个方面。有人提出,后续应加入Danube 3、Danube 2等模型。有用户认为,在进行基准测试时,应展示所用设备、推理栈及推理栈的构建日期等信息,因为不同的后端会影响输出质量和性能。比如有用户分享道:“你会惊讶地发现,除非所有后端相同,否则设备不同,质量肯定会有所差异,而在边缘/移动设备中,后端相同的情况很少见。操作代码会因后端不同而不同,这就为出现错误或影响输出的变化提供了机会。”
还有用户表示,排行榜中有些模型在特定设备上的表现并不理想,比如Feztopia称在自己的安卓设备上,Gemma 2 9b速度超慢,并推荐了在速度上表现更好的模型。
也有人希望能对单板计算机(SBC)进行基准测试,认为仅以内存大小衡量不够准确,比如OrangeESP32x99表示自己的OPI5+虽有32G内存,但CPU限制了其性能。
此外,还有用户分享了个人使用Gemma的实践经验,证实其高质量,并对创建者表示感谢。
总之,这次关于On-Device小型语言模型排行榜的讨论,为开发者和爱好者们提供了丰富的观点和建议,有助于进一步优化和完善这个排行榜,使其更好地服务于相关领域的探索和应用。


感谢您的耐心阅读!来选个表情,或者留个评论吧!