无实际内容可翻译,仅为一个图片链接:
讨论总结
这个讨论围绕着Qwen 2.5在官方LiveCodeBench排名表中的表现展开。有对Qwen 2.5的惊叹和高度评价,也有对其相关成果的疑惑。还涉及到其他模型如Claude、o1 - mini等的性能、排名、在不同任务中的表现以及不同版本间的比较,包括模型训练数据的可靠性、模型的多样性等话题,整体氛围充满技术探讨的氛围。
主要观点
- 👍 Qwen 2.5模型表现出色
- 支持理由:如评论者用“monsters”形容Qwen 2.5模型,还有人认为它是目前最好的模型。
- 反对声音:有评论者指出Qwen存在如缺少领域知识等不足。
- 🔥 Claude在编码任务方面表现最佳,但受多种因素影响
- 正方观点:如评论者认为Claude在编码任务方面是目前最好的模型。
- 反方观点:有评论者指出Claude的表现取决于编程语言、任务类型和模型推广方式等因素。
- 💡 对于编码目的,Qwen2.5 - 32B的Q8版本与Qwen2.5 - 72B的Q4/4bit版本性能比较存在疑问
- 不同人有不同看法,有的认为72B的Q4比32B好,也有人表示个人发现32B对于一些代码任务可能比72B略好。
- 🤔 不同模型在不同编程任务中有不同表现
- 例如o1 - mini在Live bench的代码生成方面领先,但在代码补全方面表现欠佳。
- 😕 对Qwen 2.5系列取得的成果感到疑惑
- 有评论者表示对Qwen 2.5系列取得的成果感到困惑。
金句与有趣评论
- “😂 Qwen 2.5 models are monsters…”
- 亮点:生动形象地表达出对Qwen 2.5模型的惊叹之情。
- “🤔 I was and still am kind of baffled what they managed to pull in these 2.5 series.”
- 亮点:直接表达出对Qwen 2.5系列成果的疑惑。
- “👀 And if rumours are correct, 3.0 should really be something. Maybe go - to SOTA open - source LLM for everyone!!!”
- 亮点:对Qwen 3.0充满期待,认为可能成为开源大语言模型的首选。
- “😎 Meanwhile, OpenAI showcases its latest version of blackbox to a select few who are willing to pay premium.”
- 亮点:指出OpenAI的最新版本仅向少数付费者展示这一现象。
- “🤨 My only issue is that I find 4o useless as heck, sonnet is the first one that actually works for me, so I don’t know if beating 4o reeeaaallly means anything.”
- 亮点:在比较不同模型有用性时提出独特观点。
情感分析
总体情感倾向较为复杂,既有对Qwen 2.5等模型表现好的积极情感,如惊叹、期待;也有疑惑等中性情感。主要分歧点在于不同模型在各项任务中的性能表现以及不同版本间的比较,可能的原因是不同用户有不同的使用场景、需求以及对模型评价的标准不同。
趋势与预测
- 新兴话题:像假设400B参数规模的模型超越o1这种对大参数规模模型性能的探讨可能会引发后续讨论。
- 潜在影响:对人工智能模型的开发和优化有着积极的影响,有助于开发者根据不同的任务需求和性能表现来改进模型或者选择合适的模型进行相关应用的开发。
详细内容:
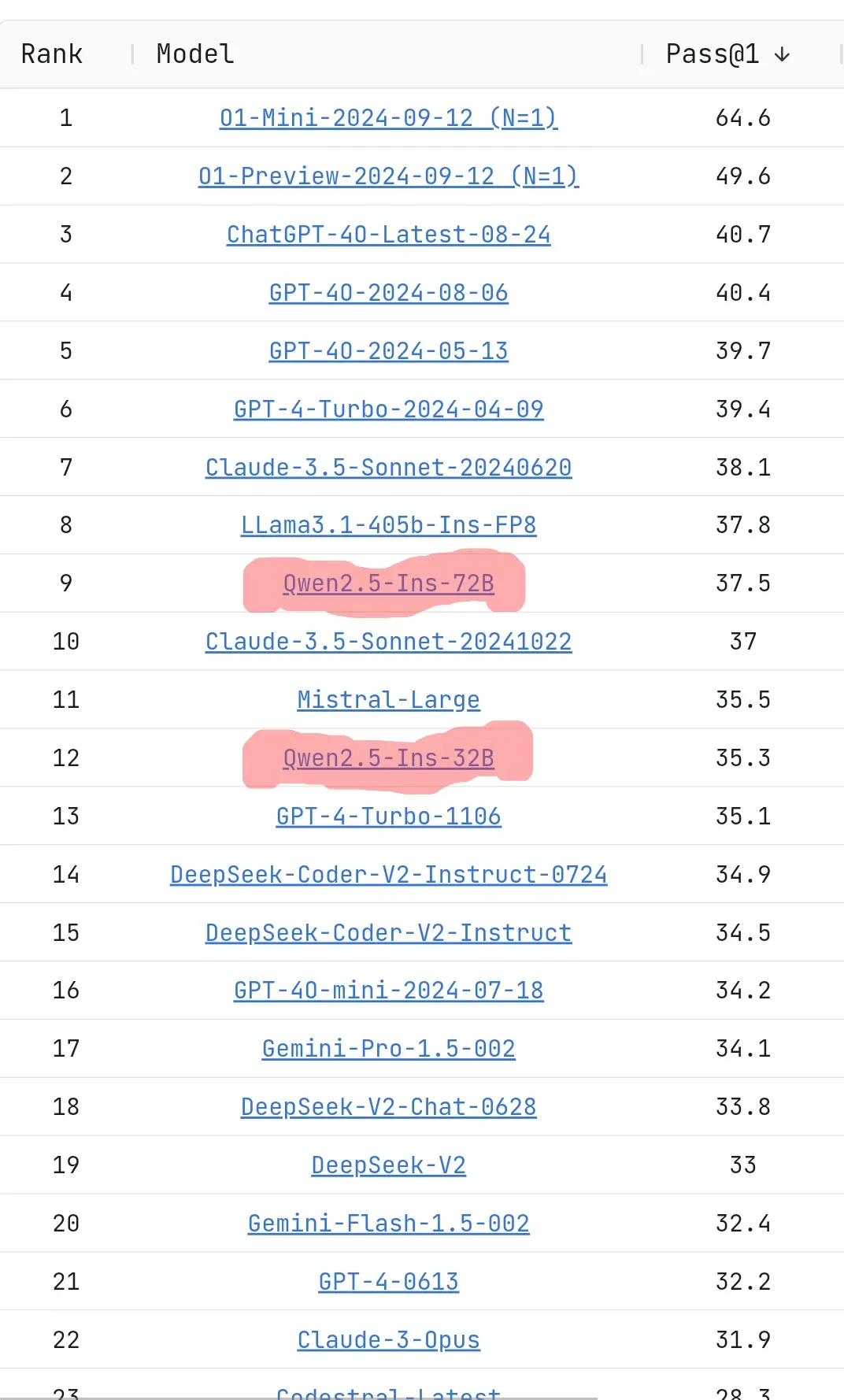
标题:Reddit 上关于 Qwen 2.5 在 LiveCodeBench 排名的热议
在 Reddit 上,一张关于 Qwen 2.5 在 LiveCodeBench 领导板的排名表引发了众多网友的热烈讨论。该帖子获得了大量的关注,评论数众多。讨论主要围绕不同模型的性能对比、实际使用体验以及对未来发展的期待等方面展开。
在讨论焦点与观点分析中,有人认为 Qwen 2.5 模型表现出色,堪称“怪兽”。有人对不同模型在编程任务中的表现进行了详细比较,比如有人分享道:“4o 会尝试估计代码的使用情况,但会使用不存在的语法,调用不存在的方法和函数。如果给它更多信息让它重试,它会陷入混乱,重写的内容往往离目标更远。” 还有用户表示:“Large 2 会假定自己熟悉语言和库,给出大致正确的结构,但很多细节不对。当给它更多信息重写和修复问题时,它会拒绝使用并重复输出相同的内容。”
对于 Qwen 2.5 不同版本的性能,存在不同看法。有人认为大模型 Q4 量化的质量损失最小,72B Q4 仍优于 32B;也有人通过实践发现 32B 在某些代码任务上与 72B 相当甚至略好,但 72B 运行速度太慢。
同时,关于其他模型,如 Claude 在排名中的位置引发了争议,有人认为 Claude 在编码任务中是最好的模型,远超其他;也有人认为它在第七的排名令人怀疑。
在讨论中,大家普遍认为不同模型各有优劣,适用场景也不尽相同,选择应根据具体需求和使用场景而定。


感谢您的耐心阅读!来选个表情,或者留个评论吧!