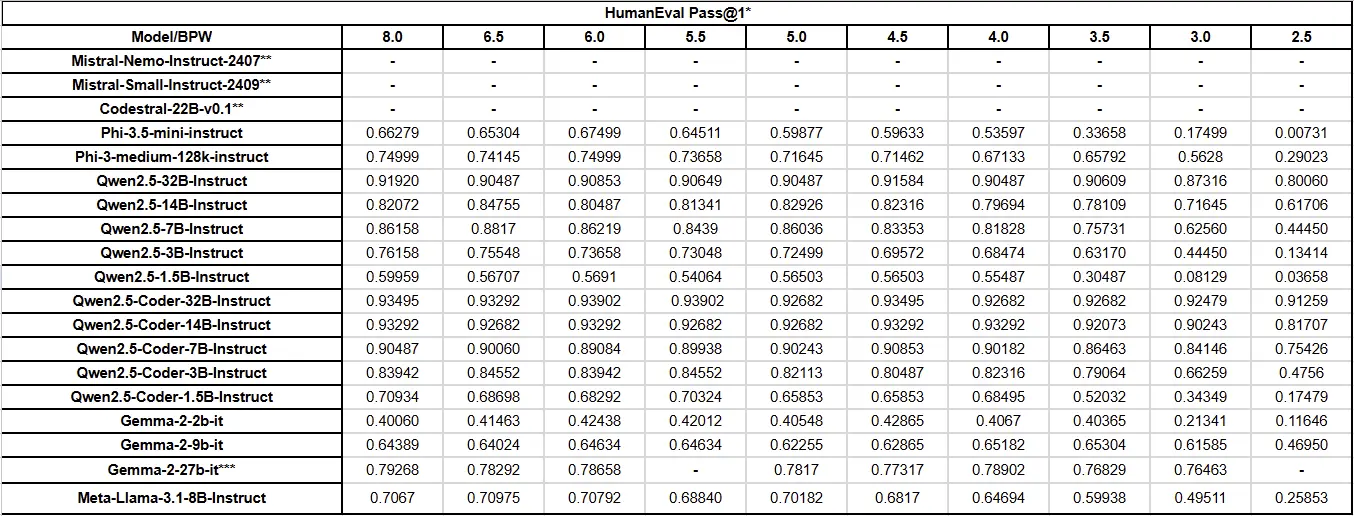
我希望有人觉得这有用。使用4070 Ti Super花费了相当长的时间。所有量化都使用exllamav2 0.2.2完成 - 唯一的例外是gemma2 27B,因为它量化速度非常慢,所以我最后在HuggingFace上下载了我能找到的EXL2量化版本。我知道HumanEval现在已经有些过时了,但exllamav2内置了它的工具,所以我很容易运行评估。
讨论总结
原帖进行了对流行本地LLMs的EXL2量化的HumanEval基准测试,展示了相关数据表格。评论中大家从不同角度进行讨论,有对模型性能在不同量化程度下表现的分享,如Qwen相关模型在不同bpw下的表现;有对量化过程对比的观点,像EXL2与AWQ的对比;还有对HumanEval本身有效性的质疑,以及关于补充数据(如VRAM使用情况)、可视化、数据可视化请求等方面的讨论,整体氛围理性且专注于技术探讨。
主要观点
- 👍 qwen 2.5 coder 14B和32B的性能在4位前不受影响
- 支持理由:通过相关测试观察得出。
- 反对声音:无。
- 🔥 EXL2在低量化方面表现优于4位和8位AWQ
- 正方观点:有人能看出两者之间的差异,认为EXL2在低量化方面表现更好。
- 反方观点:无。
- 💡 Qwen Coder模型在量化时能较好地保持性能
- 依据对原帖多种模型在量化过程中的性能表现比较得出。
- 💡 认为HumanEval基准对质量评估已无用
- 支持理由:以Qwen2.5 - Coder - 3B - Instruct的得分情况为例,认为与实际使用无关联。
- 反对声音:无。
- 💡 应在研究中加入VRAM使用情况的数据
- 支持理由:有助于进行模型/量化组合适配且性能最高之类的比较,解答模型选择问题。
- 反对声音:无。
金句与有趣评论
- “😂 It’s interesting that qwen 2.5 coder 14B and 32B aren’t affected until about 4 bits.”
- 亮点:引出对模型容量与性能关系的思考。
- “🤔 Qwen 2.5 32b coder instruct losing 2% between 8bpw and 2.5bpw is crazy”
- 亮点:指出特定模型量化过程中性能变化的惊人之处。
- “👀 我认为这恰恰说明了这个基准对于任何质量评估来说已经变得多么无用。”
- 亮点:直接表达对HumanEval基准在质量评估有效性方面的质疑。
- “😎 4bpw exl2 quants are super fast and extremly good for their size.”
- 亮点:强调exl2量化在特定量化程度下的速度和效果。
- “🧐 我需要更多的VRAM来处理32B,尽管在节省空间的2.5位时它的颜色很好看。”
- 亮点:将32B模型可视化时显存需求和可视化效果联系起来。
情感分析
总体情感倾向为中性,主要是理性地探讨技术相关的话题。主要分歧点在于对HumanEval基准有效性的看法,一部分人依据自己的观察和分析认为它无用,而原帖是基于这个基准进行的测试。可能的原因是大家从不同角度看待这个基准与实际模型性能和质量评估之间的关系。
趋势与预测
- 新兴话题:对模型操作中的参数(如温度)的关注,以及补充VRAM使用情况数据可能会成为后续讨论热点。
- 潜在影响:有助于更全面地评估模型性能,对模型选择、优化等相关技术研究工作有积极的推动作用。
详细内容:
标题:Reddit 上关于流行本地 LLM 的 HumanEval 基准量化讨论热度高
在 Reddit 上,一则题为“HumanEval benchmark of EXL2 quants of popular local LLMs (2.5 through 8.0 bpw covered)”的帖子引发了广泛关注。该帖子作者使用 4070 Ti Super 花费不少时间完成了所有量化,并提供了相关链接。帖子中还提到对 Gemma2 27B 量化耗时 9 小时。
这一话题吸引了众多讨论,点赞数和评论数众多。主要讨论方向包括不同模型在量化过程中的性能表现,以及对 HumanEval 基准测试的看法。核心问题是如何评估不同模型在不同量化水平下的实际表现,以及 HumanEval 基准测试在当前模型评估中的有效性。
讨论焦点与观点分析: 有人指出 qwen 2.5 coder 14B 和 32B 在约 4 位之前不受影响,这让人好奇这些模型在达到“饱和”之前还能容纳多少信息。有人认为这可能源于相对较短的基准任务,在实际编码任务中,小量化的 LLM 随着上下文变长,偏离指令的风险更高。 有用户表示 Qwen 2.5 32b coder 在 8bpw 和 2.5bpw 之间仅损失 2%,这令人惊讶。还有人提到在编码测试中,coder 14b q4.25 比 q8 更好。 有人认为 Qwen Coder 模型在量化时保持性能方面表现出色。但也有人觉得这个基准测试对于质量评估没什么用,比如 Qwen2.5-Coder-3B-Instruct 在 4.0 BPW 之前得分较高,这与现实世界的使用情况不符。 有人希望能将 HumanEval 扩展到更多问题。还有人提出做一个按每 GB 得分的图表,或者考虑纳入 VRAM 的使用情况来进行比较。
总的来说,讨论中对于不同模型的量化表现看法不一,对于 HumanEval 基准测试的有效性也存在争议,但这些讨论为模型的评估和优化提供了有价值的思考。


感谢您的耐心阅读!来选个表情,或者留个评论吧!