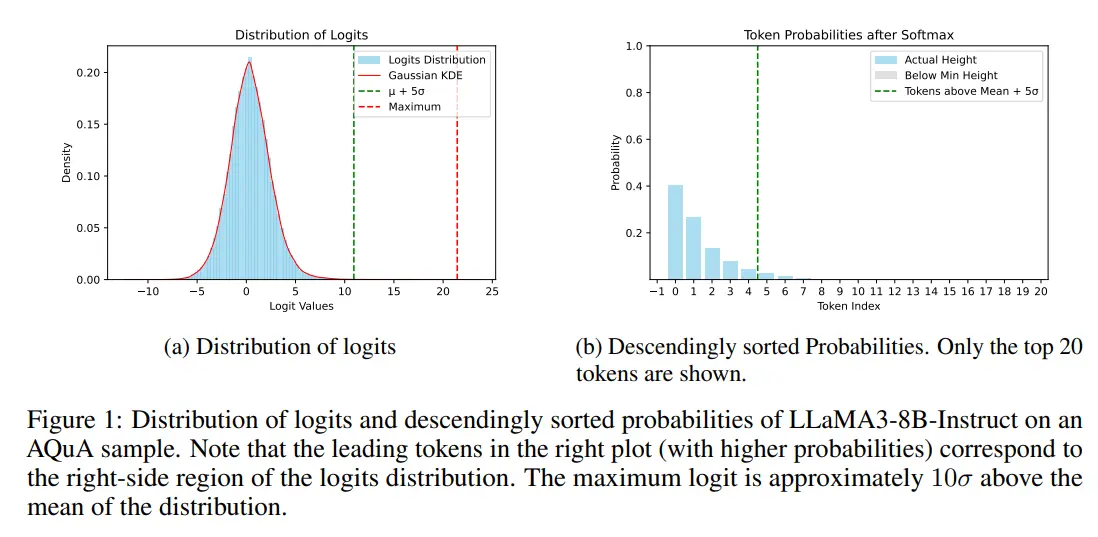
简而言之: 阈值 = logits.max(dim=-1,keepdim=True).values - n*logits.std(dim=-1,keepdim=True) logits[logits<threshold] = 负无穷 这被称为top - nsigma,直接利用logits信息过滤掉标记。 在我看来,最有趣的发现是:logits自然地被分为两个区域:高斯噪声区域和信息区域。当模型不够自信或者温度较高时,“有意义”的标记和“噪声”标记之间的差距缩小,噪声标记开始潜入采样池,降低质量。
讨论总结
帖子主要介绍了一种名为top - nsigma的新采样策略,该策略有75%的准确率。评论主要围绕这个策略展开多方面的讨论,包括对论文标题是否遵循模板的争议,与其他类似技术如Differential Transformer、TFS的相似性探讨,以及对top - nsigma方法本身的技术细节、优势(如温度不变性)等内容的交流,整体氛围偏向于技术爱好者之间的探讨。
主要观点
- 👍 认为论文标题有遵循模板之嫌。
- 支持理由:kulchacop指出论文标题像是在模仿其他论文的标题模式。
- 反对声音:Evening_Ad6637认为标题是对研究内容的直接暗示。
- 🔥 top - nsigma与Differential Transformer理念相似。
- 正方观点:二者有着相似的理念,都是将对数视为信号与噪声的组合并认为去除噪声有益。
- 反方观点:无(未提及)
- 💡 top - nsigma方法的温度不变性是最酷之处。
- 解释:无论应用何种温度,它都会采样相同数量的tokens,能适应不同token分布。
- 💡 top - nsigma方法和自己之前开发的采样器相似。
- 解释:anchortense表示与自己几个月前开发的logit阈值采样器非常相似。
- 💡 在较高温度下,固定logit阈值在过滤不连贯token方面更稳定。
- 解释:anchortense测试发现这一结果。
金句与有趣评论
- “😂 kulchacop:The paper is titled “Top - nσ : Not All Logits Are You Need”. They tried too much to follow the template.”
- 亮点:直接指出论文标题有遵循模板的嫌疑,引发后续关于标题的讨论。
- “🤔 _Erilaz:What does it even mean, strictly speaking? Like, I get the attention article reference, but they’re talking about samplers… And the grammar makes no sense. Is it some sort of Yoda talk? In a preprint? My non - native brain can’t process this title, the word order is all over the place!”
- 亮点:表达对标题语法和用词的困惑,很有代表性。
- “👀 tomorrowdawn:Due to the inherent flaw of softmax, not all logits should be considered to produce positive probabilities(which will downgrade the quality).”
- 亮点:对技术相关内容进行解释,有助于理解top - nsigma的原理。
- “💡 This reminds me a lot of [2410.05258] Differential Transformer, which has a very similar idea but applied to the Q•K attention logits.”
- 亮点:指出top - nsigma与其他技术的相似性,拓展了讨论的广度。
- “👍 The coolest part to me is the temperature invariance.”
- 亮点:强调top - nsigma方法的一个重要特性。
情感分析
总体情感倾向是较为中性的技术交流。主要分歧点在于对论文标题的看法,部分人认为标题有遵循模板之嫌,而部分人觉得标题是对研究内容的暗示。可能的原因是大家对标题的理解角度不同,有的从语言表达的创新性来看,有的从研究内容的概括性来看。
趋势与预测
- 新兴话题:top - nsigma与其他采样技术的进一步对比,如和TFS的详细比较等。
- 潜在影响:如果top - nsigma被证明更优,可能会被更多地应用到机器学习相关领域,影响模型的采样策略,进而提高模型性能。
详细内容:
标题:关于“top-nsigma”采样策略的热门讨论
在 Reddit 上,一篇题为“Another sampling strategy drops: 75% accuracy at T=3.0”的帖子引起了广泛关注。该帖子介绍了一种被称为“top-nsigma”的采样策略,它直接利用 logits 的信息过滤掉部分 tokens。原帖点赞数众多,评论区也十分热闹,主要围绕这一策略的原理、效果以及相关命名等展开了讨论。
讨论焦点与观点分析:
- 关于论文的命名,有人觉得“Top- nσ : Not All Logits Are You Need”试图遵循某种模板,有点生硬。比如,[_Erilaz] 表示不太理解,其非母语的大脑难以处理这种语序混乱的标题。而 [DeProgrammer99] 解释说,他们想表达的是“你不需要所有的 logits”,只是在模仿其他论文的标题模式。
- 对于策略本身,[tomorrowdawn] 指出由于 softmax 的固有缺陷,并非所有 logits 都应产生正概率,否则会降低质量。[_Erilaz] 理解了技术原理,即通过评估低概率 token 分布来过滤掉混入采样器的随机 tokens。
- 有人将其与其他类似研究进行了联系,比如 [fogandafterimages] 提到了 [[2410.05258] Differential Transformer],认为有相似的思路。[PickleFart56] 分享了相关论文 https://arxiv.org/html/2410.02703 ,指出有很多论文表明当模型关注所有 tokens 时性能会下降。
- [placebomancer] 认为该策略中温度不变性很酷,无论对 logits 应用何种温度,采样的 tokens 数量相同。还表示要实际测试一下,初步认为这可能是对 min-p、TFS 等采样技术的改进。
- [anchortense] 提到这与自己几个月前开发的 logit 阈值采样器非常相似,当时测试发现固定的 logit 阈值在较高温度下更稳定。
在这场讨论中,大家对“top-nsigma”采样策略的原理和效果进行了深入探讨,虽有不同看法,但对于技术的追求和探索是共同的。
总之,Reddit 上的这场讨论为“top-nsigma”采样策略提供了多角度的思考和见解,有助于推动相关技术的发展和完善。


感谢您的耐心阅读!来选个表情,或者留个评论吧!