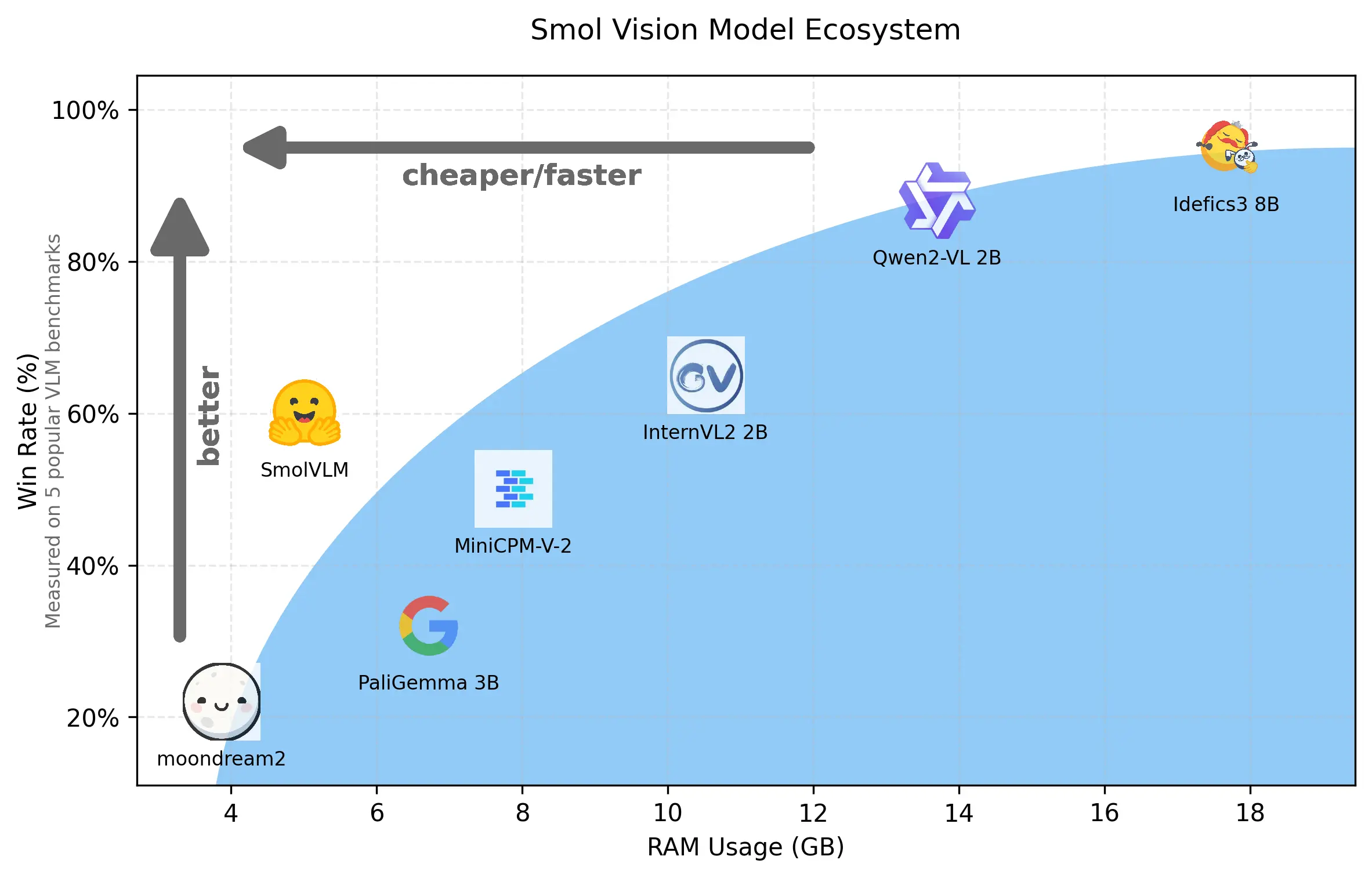
嗨!我是Andi,来自Hugging Face的一名研究员。今天我们发布SmolVLM,这是一个为设备端推理构建的小型2B视觉语言模型(VLM),在相似的GPU内存使用量和令牌吞吐量下,它的性能优于所有模型。
- SmolVLM生成令牌的速度比Qwen2 - VL快7.5到16倍。
- 其他相同规模的模型会使笔记本电脑崩溃,但SmolVLM在MacBook上可以轻松地每秒生成17个令牌。
- SmolVLM可以在Google Colab上进行微调!或者使用消费级GPU处理数百万个文档。
- 尽管SmolVLM甚至没有在视频上进行训练,但它在视频基准测试中的表现甚至优于更大的模型。
如果您想了解更多,请查看以下链接:
演示:https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
博客:https://huggingface.co/blog/smolvlm
模型:[https://huggingface.co/HuggingFaceTB/SmolVLM - Instruct](https://huggingface.co/HuggingFaceTB/SmolVLM - Instruct)
微调脚本:https://github.com/huggingface/smollm/blob/main/finetuning/Smol_VLM_FT.ipynb
我很乐意回答问题!

讨论总结
这是关于Hugging Face发布SmolVLM的讨论。大部分评论者对SmolVLM表现出兴趣,有的看好其前景,提到它在OCR、图像字幕功能方面的表现,与其他模型竞争的潜力等。同时也存在不少疑问,如在安卓系统上的运行情况,与其他模型(Mistral VLM、moondream等)的比较,还涉及到对模型的一些技术层面的探讨,像VRAM需求、基准测试数据的准确性等内容,整体氛围积极且充满探索性。
主要观点
- 👍 SmolVLM的OCR功能聚焦特定区域较好,全屏幕则变弱,图像字幕功能准确且有潜力与mini - cpm - V - 2.6竞争
- 支持理由:评论者通过自己的测试体验得出。
- 反对声音:无。
- 🔥 需要基准测试来更好地了解SmolVLM
- 正方观点:原帖数据不够全面,需要更多基准测试内容。
- 反方观点:无。
- 💡 SmolVLM在视频基准测试中胜过更大模型令人震惊
- 解释:因为它未在视频上训练却有此表现,有评论者在测试时也感到诧异。
- 💡 Smol VLMs对无视觉能力的大模型有积极作用
- 解释:可作为无视觉能力大型模型的附加组件,提升其功能或性能。
- 💡 对SmolVLM内存基准测试中Qwen - VL 2B的VRAM最低需求数据表示质疑
- 解释:评论者自身测试结果与基准测试数据不符。
金句与有趣评论
- “😂 Its OCR capabilities are pretty good. It can accurately read entire paragraphs of text if you focus on it. But the OCR capabilities fizzle out when you expand the focus to the entire screen of your PC.”
- 亮点:形象地描述了SmolVLM的OCR功能在不同情况下的表现。
- “🤔 I do think there’s lots of potential with this one. I’d go as far as to say it could rival mini - cpm - V - 2.6, which is a huge boon.”
- 亮点:对SmolVLM的潜力给予高度评价。
- “👀 SmolVLM even outperforms larger models in video benchmarks, despite not even being trained on videos.”
- 亮点:指出SmolVLM令人惊讶的性能表现。
- “😎 well we need some benchmarks or something”
- 亮点:直接表达对SmolVLM需要更多基准测试的观点。
- “🤨 I’m still experimenting with it locally and I’m getting some extremely wonky results but at the same time I feel like I’m doing something wrong.”
- 亮点:体现出评论者在本地测试模型时遇到问题的困惑。
情感分析
总体情感倾向是积极的。主要分歧点在于对SmolVLM一些性能数据(如VRAM需求等)的准确性的看法。积极的原因是多数评论者看好SmolVLM的前景,认可它的一些功能优势;而分歧则源于部分评论者在自己测试或对数据的理解上与原帖有所不同。
趋势与预测
- 新兴话题:SmolVLM与其他模型(如moondream闭源模型)比较可能会引发后续讨论。
- 潜在影响:如果SmolVLM在移动设备(如安卓)上能够成功运行,可能会对相关视觉模型在移动设备上的应用产生推动作用。
详细内容:
标题:Hugging Face 推出 SmolVLM 引发 Reddit 热议
近日,Hugging Face 的研究者 Andi 在 Reddit 上发布了关于 SmolVLM 的帖子,引起了广泛关注。该帖获得了众多点赞和大量评论。帖子主要介绍了 SmolVLM 这一为设备端推理而构建的小型 2B 视觉语言模型(VLM),强调了其在性能和资源利用方面的优势,如生成令牌速度比 Qwen2-VL 快 7.5 至 16 倍,能在笔记本电脑上稳定运行并在 Macbook 上每秒生成 17 个令牌,还可在 Google collab 上进行微调等。
讨论焦点主要集中在 SmolVLM 的性能表现、在不同设备上的运行情况以及与其他类似模型的比较。有人表示其 OCR 能力不错,能准确读取整段文字,但在扩展到整个电脑屏幕时效果会减弱,也能准确为图像添加标题。还有人提到了视觉编码器效率的调整方法,并指出分辨率调整可能对性能产生影响。有人在本地运行时遇到了一些问题,如 RTX 8000 Quadro 48GB VRAM 下的配置困惑,以及在 CPU 运行时的长时间测试。对于在 Android 设备上的运行,有人关心所需的内存,也有人探讨是否有相关的应用程序。
有人分享道:“我使用 CPU 运行 SmolVLM 时,提供的测试代码(描述两张图像)需要 4 小时,而 Qwen2VL 描述一张图像大约需要十分钟。当然,使用的注意力机制是‘eager’。”
关于 SmolVLM 与其他模型的比较,有人询问它与 Mistral VLM 的对比情况,还有人对其与 moondream 模型的优劣进行了讨论。
讨论中的共识在于大家都对 SmolVLM 的性能表现充满期待,并希望能在不同设备和场景下获得更优化的使用体验。特别有见地的观点是关于如何在不同条件下调整模型以达到更好的性能和资源利用平衡。
然而,讨论中也存在一些争议点。比如,关于 VRAM 用量的测量在内存基准测试中的准确性就引发了争议。有人认为 Qwen2-VL 模型的最小 VRAM 需求标注不准确,而相关人员解释了测量的方法和原因,并表示愿意继续探讨和改进。
总的来说,Reddit 上关于 SmolVLM 的讨论热烈且深入,为大家更全面地了解这一模型提供了丰富的视角和有价值的信息。


感谢您的耐心阅读!来选个表情,或者留个评论吧!