该基准测试(
讨论总结
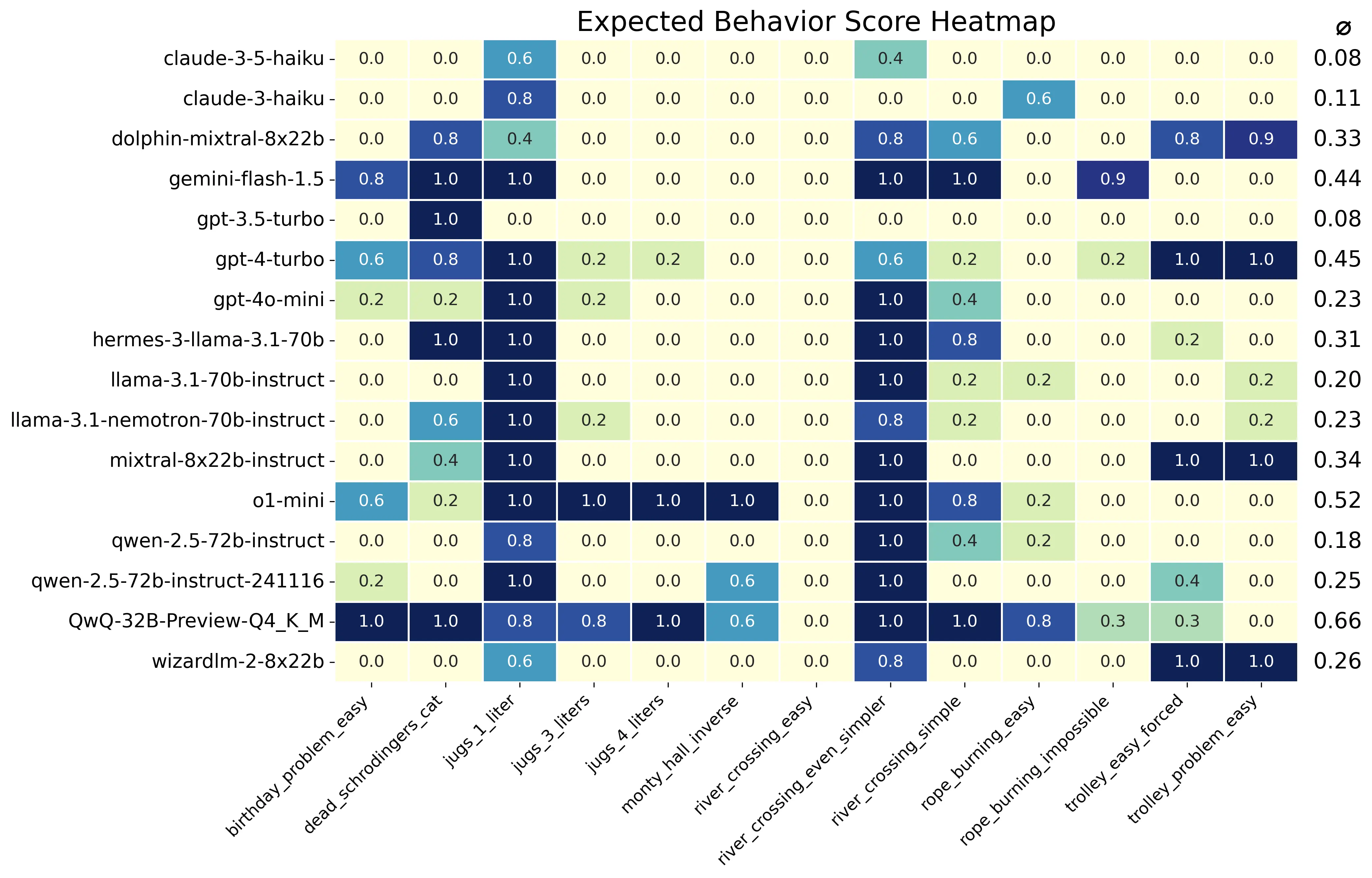
原帖作者对QwQ - 32B 4bit量化模型进行本地误导向注意力评估并取得较好结果,且该模型在测试中击败了o1 - preview和o1 - mini。评论者们从多个方面进行讨论,包括认可模型性能、对其创造性的赞赏、分享自己的测试经验、对相关模型的期待、对测试概念的肯定,也有部分评论者提到在特定运行环境下模型出现的异常情况,总体氛围积极向上。
主要观点
- 👍 QwQ - 32B 4bit量化模型在测试中表现优于其他模型
- 支持理由:原帖给出了与o1 - preview等模型对比的成绩,如平均得分0.66高于o1 - preview的0.64。
- 反对声音:无。
- 🔥 在聊天功能方面,该模型与70b模型能力相当且更具创造性
- 正方观点:评论者指出在聊天方面能与70b模型媲美且更具创造性。
- 反方观点:无。
- 💡 祝贺原帖作者完成基准测试并感谢其进行模型比较
- 解释:有评论者对原帖作者完成测试表示祝贺并感谢进行模型比较,这有助于大家对模型有更多的认识。
- 💡 QwQ在规划/推理导向用例中目前看起来很棒
- 解释:从原帖中的基准测试及评论者的认可可知该模型在这些用例中有较好表现。
- 💡 希望有小的QWQ做草稿模型
- 解释:有评论者认为这样有助于一些场景下的使用,不同模型家族在做草稿模型时效果不同。
金句与有趣评论
- “😂 在聊天方面,它能与70b相媲美且更具创造性。”
- 亮点:突出了QwQ - 32B模型在聊天方面的能力优势。
- “🤔 Congrats on finalising the benchmark!”
- 亮点:表达了对原帖作者完成基准测试的祝贺。
- “👀 DryArmPits: I’ll give it a quick try today. It seems promising.”
- 亮点:显示出评论者对该模型的兴趣和积极尝试的态度。
- “🤔 DeltaSqueezer: Thanks for testing this. I’m enjoying QwQ so far and look forward to seeing r1, but I fear that the r1 model size might be very large e.g. based on DS v2.”
- 亮点:既表达了对原帖测试的感谢,又体现了对r1模型的期待与担忧。
- “😂 NoIntention4050: Most of the times I ask a hard question it begins answering the question and then goes on weird infinite tangents and even hallucinates Human queries and begins answering them and talking to itself.”
- 亮点:生动描述了在ollama运行时模型出现的异常回答情况。
情感分析
总体情感倾向是积极的。主要分歧点较少,大部分评论者都对原帖的QwQ - 32B 4bit量化模型在测试中的良好表现表示认可,在对模型性能、创造性等方面基本持肯定态度。可能的原因是原帖中的测试结果较好,激发了大家对这个模型积极探讨的热情。
趋势与预测
- 新兴话题:对r1模型“lite”标签的深入探讨,以及对不同训练方式下该标签意义的研究。
- 潜在影响:对相关模型的改进方向可能产生影响,例如在模型规模控制、性能提升以及特定功能(如草稿模型功能)的开发等方面,也可能影响用户对不同模型的选择倾向。
详细内容:
标题:QwQ-32B 模型在本地评估中的出色表现引发Reddit热议
这篇帖子主要介绍了作者在本地对 QwQ-32B 4bit 量化模型进行了误导注意力评估,并指出其表现优于 o1-preview 和 o1-mini。该基准测试主要检验大型语言模型对知名逻辑谜题的过拟合情况。作者还提到在 3090 上运行该模型能达到约 26tk/s 的速度。此贴获得了众多关注,评论数众多,引发了广泛的讨论。
讨论的焦点主要集中在以下几个方面: 有人表示在聊天方面,QwQ 能与 70b 相媲美,且更具创造性,希望能尽快推出 70b 版本。有人恭喜作者完成基准测试,认为 QwQ 在许多规划和推理导向的用例中表现出色。还有用户分享了自己的运行体验,比如在不同任务中模型的速度表现不同,在可预测的提示(如蛇游戏)中从 35T/s 提升到 53T/s,在随机任务(写长诗)中则下降到 25 T/s。有人指出模型的话很多,内容有重复。也有人探讨了不同模型之间的差异,以及模型的量化和优化等问题。 有用户认为对于使用草稿模型,标记器需要相同,因此需要相同的模型家族。还有人提到使用 ktransformers 可能有助于提高运行速度,但对于 6GB VRAM 则无法适用。有人对从 ollama 运行的结果感到奇怪,会出现回答跑题和幻觉的情况。有人认为 GPT4 表现良好是因为未过度微调以及本身是更大的模型。有人期待 QwQ 的 r1 版本,并好奇其与 QwQ 的比较结果。有人询问作者在测试中使用的具体方法。
讨论中的共识在于大家都对 QwQ 模型的表现充满兴趣,并期待其进一步的发展和优化。特别有见地的观点是对 GPT4 表现良好原因的分析,丰富了对于模型性能的理解。
总的来说,这次关于 QwQ 模型的讨论展现了大家对于语言模型性能和优化的深入思考和探索。


感谢您的耐心阅读!来选个表情,或者留个评论吧!