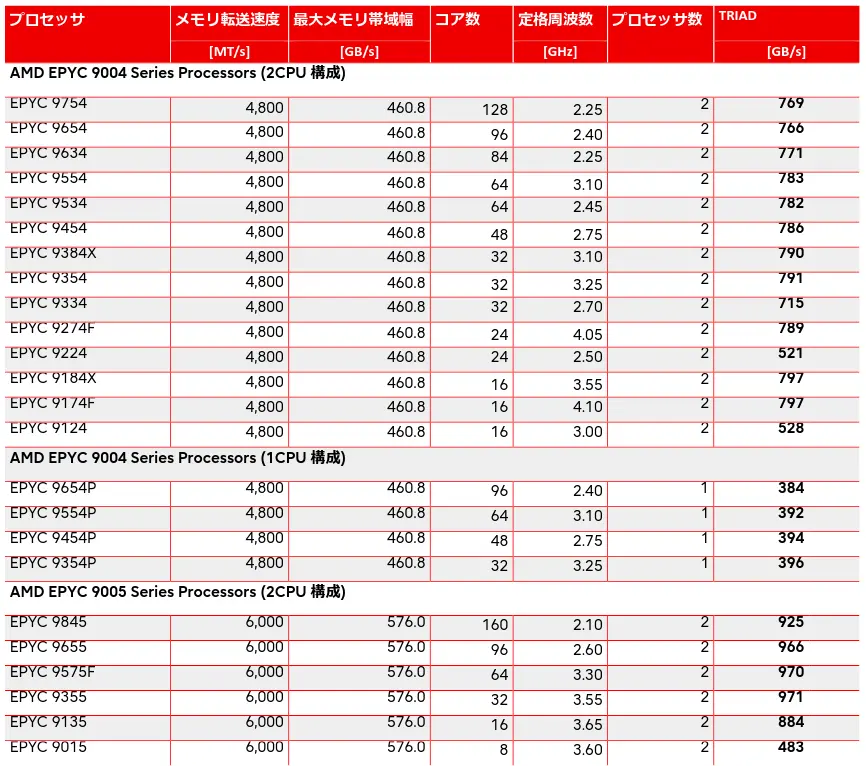
我们来自富士通的日本朋友对他们的Epyc PRIMERGY RX2450 M2服务器进行了基准测试,并分享了一些Epyc Turin的STREAM TRIAD基准测试值(表格底部):
讨论总结
主题围绕Epyc Turin服务器的基准测试结果展开。一方面有人关注数据到实际性能的转化和二手市场情况,另一方面在与LLM相关的话题中深入探讨了CPU性能、内存带宽等方面的多种情况,整体氛围是理性分析与交流。
主要观点
- 👍 希望看到测试数据转化为实际性能。
- 支持理由:这样能更直观地了解产品真实能力。
- 反对声音:无。
- 🔥 不要低估LLM的处理能力。
- 正方观点:LLM处理需要大量处理能力,即使内存带宽够CPU也未必能饱和。
- 反方观点:无明确反对,但有人要求提供证据。
- 💡 32核Epyc 9374F在llama.cpp中无饱和内存带宽问题,16核9135可能有问题。
- 解释:可能与不同核心数相关的处理能力差异有关。
- 💡 CPU卸载不只是受内存速度瓶颈。
- 解释:还需要有东西进行计算以填充缓存等多种因素。
- 💡 在处理流程中加入GPU是可行的。
- 解释:可以弥补CPU在某些方面的不足。
金句与有趣评论
- “😂 Would be cool to see how this translates over to real performance.”
- 亮点:表达了对测试数据实际应用的期待。
- “🤔 astralDangers:Don’t underestimate how much processing power is needed for a LLM. Just because the memory bandwidth is there it doesn’t mean the cpus can saturate them, especially with floating point operations.”
- 亮点:强调在LLM中不能仅看内存带宽判断CPU能力。
- “👀 astralDangers:There’s a myth here that CPU offloading is bottlenecked by only ram speed.. something has to do all the calculations to populate the cache.”
- 亮点:打破了关于CPU卸载瓶颈的错误观念。
情感分析
总体情感倾向是较为中性的探讨。主要分歧点在于对CPU性能相关观点缺乏证据的质疑,可能原因是在技术讨论中需要严谨的数据和实例支撑观点。
趋势与预测
- 新兴话题:在处理LLM中不同核心数CPU与GPU的组合优化。
- 潜在影响:可能会影响到相关服务器在LLM处理场景中的选型策略。
详细内容:
《Epyc Turin 内存带宽基准值引发的热烈讨论》
在 Reddit 上,一则关于 Epyc Turin 内存带宽基准值的帖子引起了广泛关注。该帖子介绍了日本富士通对其 Epyc PRIMERGY RX2450 M2 服务器的基准测试,并分享了 Epyc Turin 的 STREAM TRIAD 基准值(位于表格底部)。相关链接:[Epyc Turin STREAM TRIAD 基准结果]([图片描述: Error processing image: Connection error.]) 完整报告在这里(日语):https://jp.fujitsu.com/platform/server/primergy/performance/pdf/wp-performance-report-primergy-rx2450-m2-ww-ja.pdf 。此结果为双 CPU 配置和 6000 MT/s 内存的情况,相对便宜(1214 美元)的 Epyc 9135 达到了 884 GB/s 的惊人值,即每个插槽超过 440 GB/s。而最便宜的 Epyc 9015 每个插槽约 240 GB/s,高端型号在双插槽系统中几乎达到 1 TB/s,与 Epyc Genoa 家族相比有显著增加。但发帖者表示想测试 Epyc Turin 系统与 llama.cpp,却找不到可租用的 Epyc Turin 裸金属服务器。此贴获得了众多点赞和大量评论,引发了一系列关于 Epyc Turin 性能的讨论。
讨论焦点主要集中在其实际性能表现、在 LLM 中的应用以及与 GPU 结合的可能性等方面。有人表示很期待看到这些数据如何转化为实际性能,不过认为其进入二手市场还需一段时间。也有人提出不能低估 LLM 所需的处理能力,虽然内存带宽存在,但 CPU 未必能充分利用,尤其是在浮点运算中,还指出 CPU 卸载并非仅受内存速度限制,计算以填充缓存也很关键。还有用户分享称自己的 32 核 Epyc 9374F 在 llama.cpp 中能充分利用内存带宽,但 16 核 9135 可能存在问题。有人则认为对于推理,情况并非如此,大多数桌面 CPU 与内存带宽有近乎线性的缩放关系,这意味着它们甚至未充分利用 ALU,对于较小的 EPYC 来说问题更小。此外,有人探讨能否在系统中添加相对较小的 GPU 用于提示处理,有人回应称这取决于具体使用场景,对于专业工作处理大量数据可能不太有用。还有人提到 CPU 能达到不错的提示处理速度,比如 7B 模型可达每秒 100 个令牌。但有人质疑这是否算好,认为低端 GPU 表现会更出色。
讨论中的共识在于大家都对 Epyc Turin 的性能表现充满好奇和期待。特别有见地的观点是关于 CPU 在不同场景下对内存带宽的利用以及与 GPU 结合的利弊分析,这些观点丰富了对 Epyc Turin 应用前景的探讨。然而,关于其在不同模型和应用中的具体表现仍存在争议,需要更多实际测试和数据来进一步明确。


感谢您的耐心阅读!来选个表情,或者留个评论吧!