我在Hugging Face平台上试过几个(开源语音合成模型),但到目前为止都不太满意。
- XTTS - V2,自带语音效果很差,已停止开发所以很难运行和使用。
- StyleTTS,在平台上仅限于生成短音频片段。很难说它是否好用。
- F5 - TTS,在Hugging Face平台上设置困难且声音机械。
就易用性和质量而言,我最喜欢的是Piper TTS:https://piper.ttstool.com。hfc - female语音在速度和模型大小方面表现惊人。
但与ElevenLabs之类的(语音合成产品)相比……哎呀。我发现我试过的都很糟糕。还有其他我可以使用的选择吗?
编辑: EdgeTTS现在让我很惊喜。非常酷!https://huggingface.co/spaces/eswardivi/Edge_TTS
二次编辑: 啊,太棒了。这里有个排名。https://huggingface.co/spaces/Pendrokar/TTS - Spaces - Arena
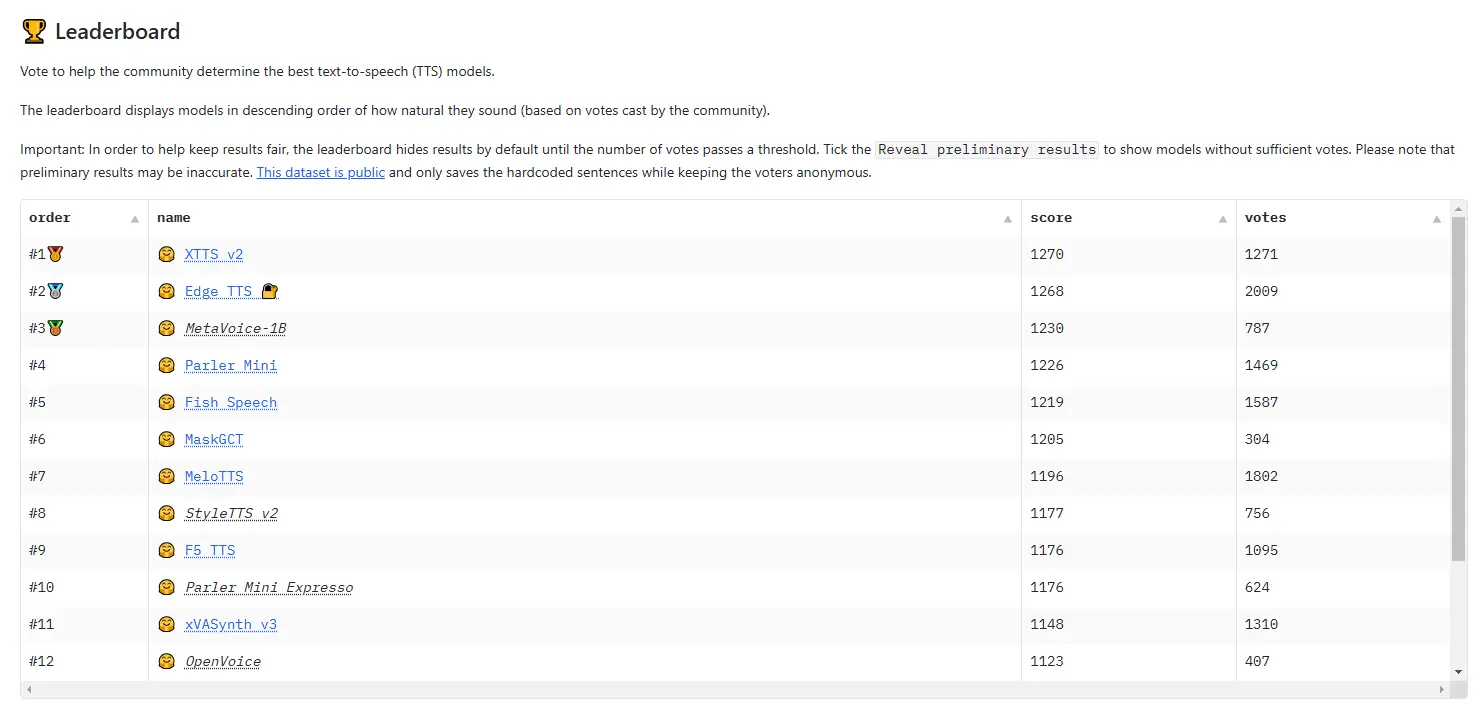
三次编辑: 这里有另一个竞赛排行榜:https://huggingface.co/spaces/TTS - AGI/TTS - Arena ElevenLabs正如人们所料表现出众。 https://preview.redd.it/8e30cphbx34e1.png?width = 1483&format = png&auto = webp&s = 5b4019adc43e690c6601ab7e36f831a089a560df
讨论总结
原帖作者尝试了多个开源TTS模型后不太满意,于是询问哪个开源TTS模型最好,众多评论者纷纷给出自己的看法。有人推荐GPT - SoVITS并介绍其设置和训练效果;有人不认同原帖对F5 - TTS机械感的评价并分享提升语音质量的方法;还有人分享自己测试其他模型的体验,如Suno’s Bark、XTTSv2等。此外,也有推荐Tortoise模型、fish.audio工具等的评论,同时大家围绕不同模型的优劣展开讨论,整体氛围较为积极且充满技术交流的氛围。
主要观点
- 👍 GPT - SoVITS是较好的开源TTS模型
- 支持理由:设置极其容易,有预安装依赖且无需技能.bat启动器,训练后效果惊人
- 反对声音:不训练的话无法胜过F5 - TTS
- 🔥 不认同F5 - TTS机械感的说法
- 正方观点:自己的体验觉得F5 - TTS不机械
- 反方观点:原帖作者觉得在Hugging Face空间上声音机械
- 💡 基础版XTTSv2较差,克隆语音后效果变好
- 解释:评论者分享自己使用XTTSv2的体验,发现克隆语音后质量提升
- 🤔 推荐Tortoise模型有不错的质量但速度很慢
- 解释:在原帖作者寻求好的开源TTS模型下推荐,同时指出其速度缺陷
- 😎 推荐fish.audio用于创建自定义语音
- 解释:评论者称在Pinokio上创建自定义语音超级容易
金句与有趣评论
- “😂 GPT - SoVITS Hands down my favourite.”
- 亮点:直接表明对GPT - SoVITS模型的喜爱。
- “🤔 F5 robotic? I couldn’t disapprove more”
- 亮点:鲜明地表达对F5 - TTS机械感说法的反对态度。
- “👀 Base XTTSv2 is pretty trash, but it becomes surprisingly good when you start cloning a voice on top of it.”
- 亮点:形象地描述了XTTSv2在克隆语音前后的效果差异。
- “😏 Tortoise? It seemed to offer decent quality, but as its name implies, was slow as hell.”
- 亮点:幽默地指出Tortoise模型速度慢的特点。
- “💥 calvedash: fish.audio is super easy on Pinokio to use for creating custom voices”
- 亮点:强调fish.audio创建自定义语音的容易程度。
情感分析
总体情感倾向是积极的,大家积极分享自己的观点和经验。主要分歧点在于对某些模型的评价,如对F5 - TTS是否机械、Piper TTS是否优于其他模型等方面存在不同看法。可能的原因是大家使用模型的场景、需求以及个人对语音质量的主观感受不同。
趋势与预测
- 新兴话题:像4o那样的“真正多模态”模型在开源TTS领域的发展潜力。
- 潜在影响:如果开源TTS有更多突破,可能会对语音合成相关的应用场景(如语音助手、有声读物制作等)产生积极影响,提高语音质量和用户体验。
详细内容:
标题:探寻最佳开源语音合成模型的激烈讨论
在Reddit上,一篇题为“Which Open Source TTS model is the best?”的帖子引起了广泛关注。该帖子作者尝试了Hugging Face spaces上的多种语音合成模型,如XTTS-V2、StyleTTS和F5-TTS等,但都不太满意。作者认为Piper TTS在易用性和质量方面表现不错,但与ElevenLabs相比仍有差距。此帖获得了众多评论和讨论,点赞数和评论数众多。
讨论的焦点主要集中在各种语音合成模型的优缺点以及如何优化使用。有人称赞GPT-SoVITS是自己的最爱,并且分享了相关的设置和训练经验。也有人对F5-TTS的声音效果提出不同看法,认为存在背景中的奇怪声音。还有用户提到使用Audacity和openVino AI插件来优化声音,并强调选择合适的声音和样本时长的重要性。
比如,有用户分享道:“我认为[Suno’s Bark]是我之前测试时最喜欢的,但设置起来非常麻烦。我找到的唯一像样的实现是[gitmylo’s audio-webui]。”
同时,对于RVC(基于检索的语音转换)也有诸多讨论。有人认为大多数语音模型一般,除非添加克隆功能,在可预见的未来,支持RVC的东西可能会超越原始的AI生成语音。但也有人对RVC不太了解,认为相关的开发主要来自中国/亚洲,缺乏足够的文档。
关于如何微调模型,有人推荐使用[alltalk_tts]并启动实例,通过其前端来了解功能,也有人认为微调受益于5分钟以上的音频。
在众多观点中,也存在一些共识。比如大家都希望能够找到高质量、低成本且易于使用的语音合成模型。而一些独特的观点,如将语音合成应用于音乐制作等,丰富了讨论的内容。
总之,关于最佳开源语音合成模型的讨论仍在继续,大家都在期待这一领域能有更大的突破和更优质的产品出现。


感谢您的耐心阅读!来选个表情,或者留个评论吧!