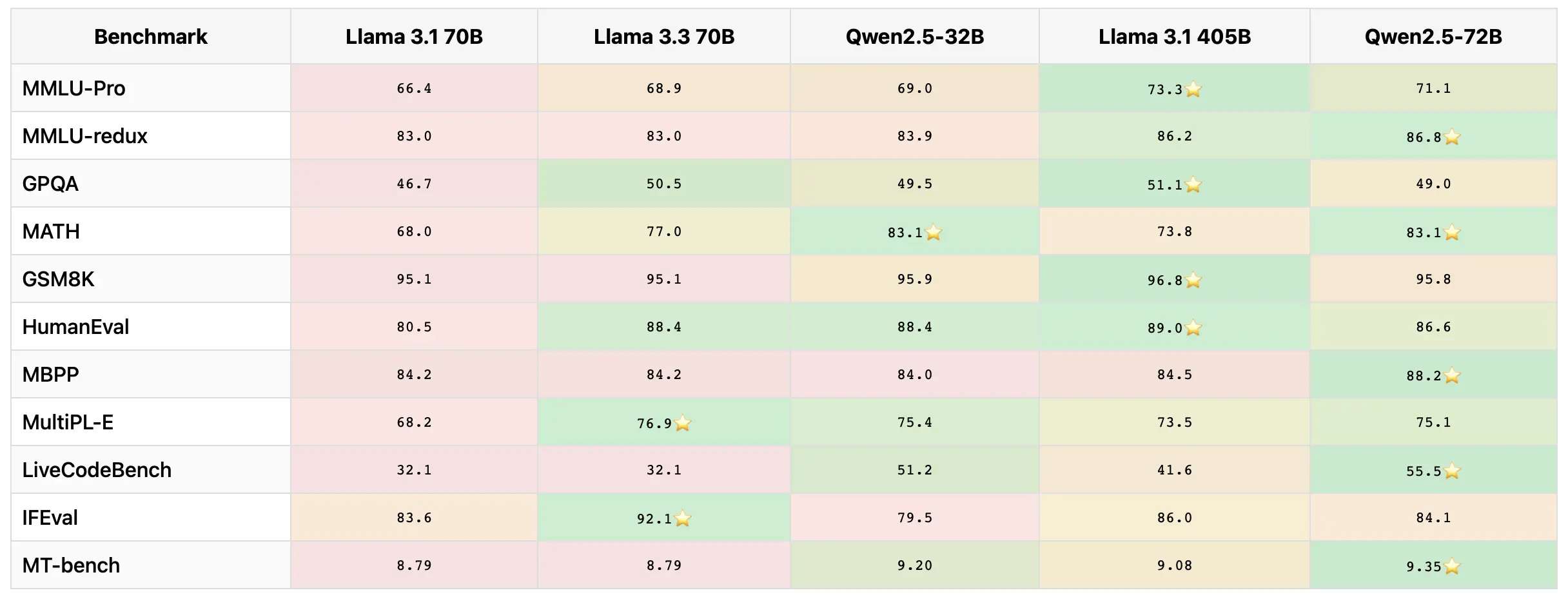
我看到有人称Llama 3.3是一场革命。继之前的qwq与o1以及Llama 3.1与Qwen 2.5对比之后,这里为我们这些难以理解纯数字的人提供了Llama 3.3 70B基准分数与相关模型的可视化展示。
讨论总结
这是一个关于Llama 3.3和Qwen 2.5对比的讨论。大家从多个角度进行探讨,包括模型性能在不同语言和场景下的表现、模型的安全性、是否存在偏见等。既有基于自身测试经验给出的观点,也有对模型未来发展的期待与怀疑,整体氛围比较积极,充满技术交流的氛围。
主要观点
- 👍 Llama 3.3在波兰语表现好,Qwen 2.5 72B在波兰语不可用。
- 支持理由:评论者PrivacyIsImportan1通过自己的测试得出此结论。
- 反对声音:无。
- 🔥 不认为Llama 3.3是革命,只是逐步改进。
- 正方观点:从之前版本的改进情况看,只是逐步提升而非革命式发展。
- 反方观点:有人认为Llama 3.3必须是革命才能成为OpenAI杀手,否则没什么可谈。
- 💡 每次提及Qwen就会引发中美之争。
- 解释:评论者Mitchel_z指出这种现象经常发生,偏离模型本身功能价值探讨。
- 👍 在编码方面Nemotron比Llama 3.3表现好。
- 支持理由:mythicinfinity在编码方面的测试体验。
- 反对声音:无。
- 🔥 Llama 3.3的意义在于训练技术改进而非原始结果。
- 正方观点:iKy1e认为通过改变训练后指令调整有很大意义。
- 反方观点:-p - e - w - 指出Llama 3.3发布公告中的提升说法与实际表格不符。
金句与有趣评论
- “😂 The best part of llama is that it’s made in the USA and therefore allowed on my company machine.”
- 亮点:体现出一种独特的认为美国制造是优势的观点。
- “🤔 My gut feeling is that Qwen was more optimized for benchmarks, while Llama 3.3 is more optimized towards general everyday use - cases.”
- 亮点:从优化方向对两个模型做出了比较。
- “👀 Llama 3.3 looks good. Qwen scores are inflated. it does not perform that well.”
- 亮点:简单直接地对比了两个模型的表现与分数。
- “😂 It has to be a revolution, because if its not then it cant be an "OpenAI Killer", and if its not an "OpenAI Killer", what would we even talk about?”
- 亮点:反映出对Llama 3.3成为OpenAI杀手的期待。
- “🤔 For me it has to talk natural and make sense.”
- 亮点:提出对语言模型更看重自然对话和表意合理的能力。
情感分析
总体情感倾向积极,大家积极分享测试经验和观点。主要分歧点在于对Llama 3.3是否是一场革命的看法,一部分人认为它有很大改进是革命式发展,而另一部分人觉得只是逐步提升。还有在模型性能对比方面,如在不同语言场景下两个模型谁更优存在不同观点,这可能是由于大家的测试环境、测试数据和使用场景的不同导致的。
趋势与预测
- 新兴话题:对Llama 4系列的期待以及推测相关模型的出现。
- 潜在影响:如果Llama 4系列真的推出,可能会改变当前的模型竞争格局,对相关应用开发、人工智能技术发展等产生推动作用。
详细内容:
《Llama 3.3 与 Qwen 2.5 引发的热门讨论》
在 Reddit 上,一则关于“Llama 3.3 与 Qwen 2.5”的帖子引发了广泛关注。该帖子提供了这两个模型的相关比较信息,并附上了一些链接,如qwq vs o1和Llama 3.1 vs Qwen 2.5。帖子获得了众多点赞和大量评论,主要讨论了这两个模型在性能、适用性、地域因素以及训练数据等方面的差异。
讨论焦点与观点分析如下: 有人认为Llama的优势在于其产于美国,能在公司机器上使用,但也有人反驳称这不能成为其优越的理由。有人指出LLM的安全性是个关键问题,在高安全环境下不应单纯依赖模型输出,而应多人审核。还有观点认为每个模型都有其优势,如有人觉得Llama在知识储备和语言理解方面更强,而Qwen更智能。有人分享了在波兰语测试中Llama 3.3表现出色,而Qwen 2.5 72B无法使用的经历。对于模型的优化方向,有人认为Qwen更针对基准测试,而Llama 3.3更适用于日常使用。有人提到不同模型在处理特定任务时的表现,如在多模态任务中,不同模型的表现各有优劣。同时,关于模型的量化和性能权衡,以及训练数据和版权等问题也引发了热烈讨论。
总的来说,这场讨论呈现了对Llama 3.3和Qwen 2.5的多角度分析和评价,为用户更全面地了解这两个模型提供了丰富的视角。但讨论中对于模型的优劣仍存在诸多争议,未来还需更多的实践和研究来明确它们的真正价值。


感谢您的耐心阅读!来选个表情,或者留个评论吧!