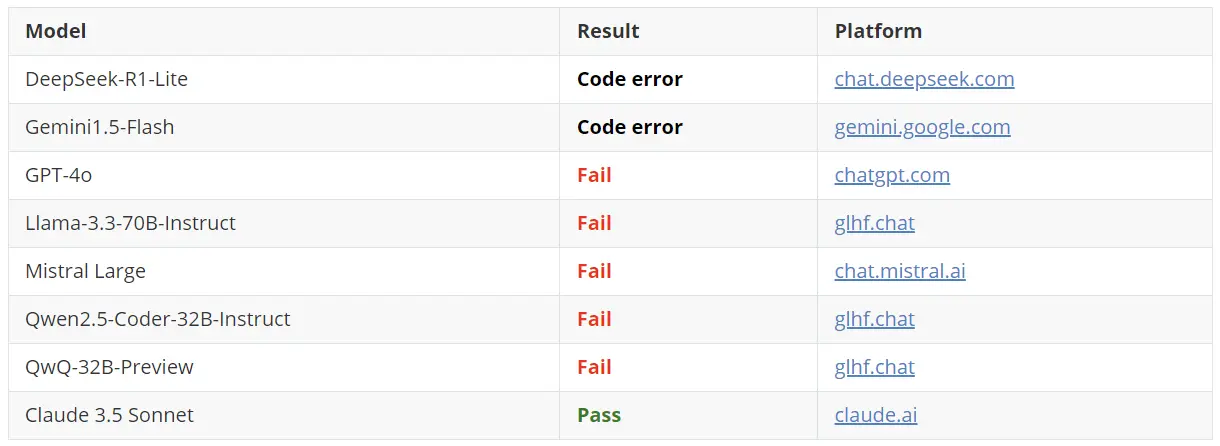
问题:编写一个Python程序,绘制从左下角到右上角的对角线。并且当拖动该线向左或向右移动时,移出屏幕的线部分必须从另一侧重新出现。每个模型只允许一次尝试。结果:
讨论总结
原帖提到一个特定的Python编程任务,各模型只有一次尝试机会,结果Claude是唯一给出正确答案的模型。评论中有人赞同Claude的独特性,也有人提出单次尝试规则不合理应多次试验。此外,还涉及到不同模型如athene - v2 - chat、Gemini等在相关任务中的表现,Claude闭源的遗憾,以及因付费墙等因素导致尝试失败等情况,整体讨论氛围比较务实,大家分享自己的观点和经验。
主要观点
- 👍 Claude有其独特之处
- 支持理由:在解决特定Python编程问题上表现突出,有用户尝试其他模型后总是选择Claude。
- 反对声音:有用户从ChatGPT切换过来使用Claude后,发现存在速度慢、过载等问题,未发现与ChatGPT有很大区别。
- 🔥 单次尝试的规则在仅进行一次模型尝试时不合理
- 正方观点:仅靠单次尝试就下结论不够全面准确,应针对每个模型开展多次试验,并报告成功试验的数量。
- 反方观点:无(评论中未发现明显反对观点)
- 💡 athene - v2 - chat能够正确完成特定Python程序任务
- 解释:评论者指出athene - v2 - chat(开源)能够正确完成任务,并给出了代码链接。
- 💡 认为Gemini 1.5 Pro在代码操作方面表现不错
- 解释:评论者看到该模型在代码操作方面表现好得出乎意料。
- 💡 闭源是一件遗憾的事情
- 解释:针对Claude是闭源这一情况,有评论者表示遗憾,也有回复者表示即便开源自己也无法运行。
金句与有趣评论
- “😂 Claude is really something else.”
- 亮点:简洁地表达出Claude的独特性。
- “🤔 Fully agree. I tried other models but always end with Claude.”
- 亮点:强调了Claude在众多模型中的优势,即使尝试过其他模型最终还是会选择Claude。
- “👀 Kind of silly to only allow each model a single attempt if you’re only going to try each model once.”
- 亮点:直接指出原帖中单次尝试规则的不合理性。
- “😉 I’ve seen something in "Gemini 1.5 Pro" that I honestly didn’t expect to be so good in code operations…”
- 亮点:分享对Gemini 1.5 Pro在代码操作方面表现的惊喜。
- “😒 Too bad it’s closed source”
- 亮点:表达对Claude闭源的态度。
情感分析
总体情感倾向比较复杂。一方面,部分人对Claude表示认可和赞赏,有积极的情感倾向;另一方面,也有人对单次尝试规则表示质疑,对Claude闭源表示遗憾,对一些模型的测试失败感到失望,存在消极情感倾向。主要分歧点在于Claude是否真的优于其他模型,以及测试规则是否合理。可能的原因是不同用户使用模型的场景、需求和体验不同。
趋势与预测
- 新兴话题:可能会有更多关于未尝试模型(如Qwen 2.5 72B Instruct)在特定任务中的表现讨论,以及对各模型在不同编程场景(如Swift / iOS编程)下的适用性研究。
- 潜在影响:对模型开发者来说,用户的反馈可能促使他们改进模型性能、优化评估规则;对用户而言,能更好地了解各模型的优缺点,选择更适合自己需求的模型。
详细内容:
标题:关于模型绘制对角线代码的热门讨论
在 Reddit 上,一则关于各模型能否正确编写绘制从左下角到右上角的对角线,并在拖动时实现特定效果的代码的帖子引发了广泛关注。该帖子获得了众多评论和讨论。
帖子中提供了包括 DeepSeek、Gemini、GPT、Llama、Mistral、Qwen、QwQ、Claude 等多个模型的代码链接。有人称赞 Claude 表现出色,也有人尝试了其他模型但效果不佳。比如,有用户分享道:“我尝试了其他模型,但最终还是觉得 Claude 更好。”
讨论的焦点主要集中在不同模型的表现差异以及代码的准确性和效果上。有人认为只给每个模型一次尝试机会不太合理,应该进行多次试验并报告每个模型的成功次数。还有用户指出某些模型虽然在某些方面表现不错,但在特定任务中可能存在不足。例如:“我在‘Gemini 1.5 Pro’中看到了一些没想到在代码操作中会这么好的东西……试试这个模型看看效果如何?”
有用户提到“Athene - v2 - chat(开源)能够正确完成任务,并提供了相关代码链接。”但也有人表示一些模型由于是闭源的而存在限制。
有人分享个人经历,称自己使用 Claude 较多,但其在某些方面仍有不足。也有人对不同模型的价格和性能进行了比较和讨论。
总体而言,这次讨论展示了大家对于不同模型在特定代码任务中的表现的关注和探讨,也反映出在模型选择和应用中的复杂性和多样性。但究竟哪个模型在这类任务中最为出色,仍没有一个明确的定论。


感谢您的耐心阅读!来选个表情,或者留个评论吧!