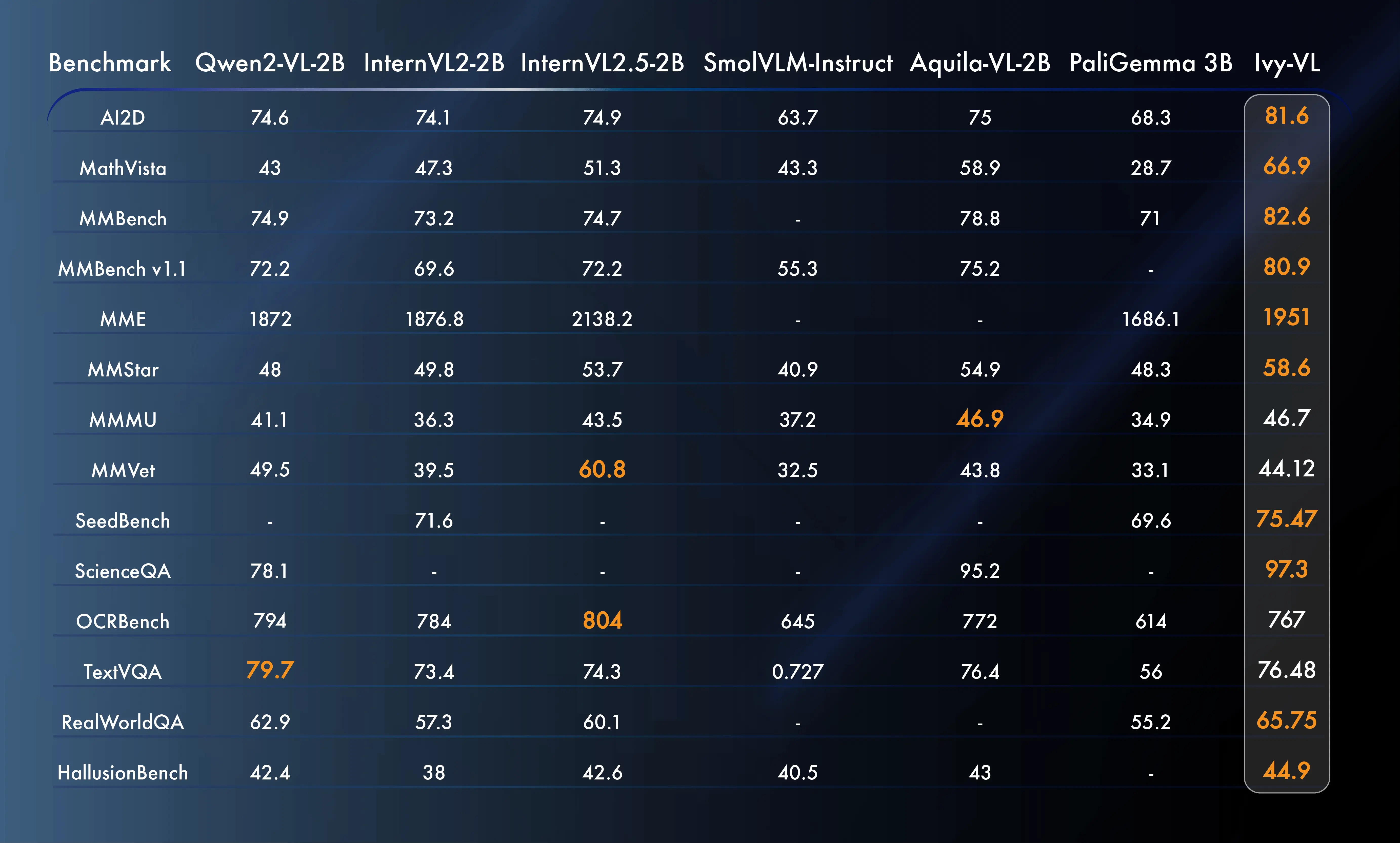
Ivy - VL是一个仅含3B参数的轻量级多模态模型。它接受图像和文本输入以生成文本输出。由于其轻量级设计,它可被部署在诸如智能眼镜和智能手机等边缘设备上,在多模态任务保持强劲性能的同时具备低内存占用和高速度。一些知名的小模型包括[PaliGemma 3B](https://huggingface.co/google/paligemma - 3b - mix - 448)、Moondream2、[Qwen2 - VL - 2B](https://huggingface.co/Qwen/Qwen2 - VL - 2B)、[InternVL2 - 2B](https://huggingface.co/OpenGVLab/InternVL2 - 2B)以及[InternVL2_5 - 2B](https://huggingface.co/OpenGVLab/InternVL2_5 - 2B)。Ivy - VL在多个基准测试中表现优于它们。[https://huggingface.co/AI - Safeguard/Ivy - VL - llava](https://huggingface.co/AI - Safeguard/Ivy - VL - llava)
讨论总结
帖子是关于CMU和Stanford发布的3B视觉语言模型Ivy - VL,评论者们提出了各种问题并表达了不同观点。有对模型技术方面如是否有论文、训练数据集的疑问,对模型用途及能力的探讨,也有人质疑模型的真实性,还有对模型性能好奇并表示惊叹的,整体讨论氛围理性客观。
主要观点
- 👍 对Ivy - VL模型的性能表示惊叹。
- 支持理由:直接表达“This is amazing performance.”。
- 反对声音:无。
- 🔥 质疑模型Ivy - VL的真实性。
- 正方观点:相关人员无历史记录、无论文、AI safeguard账号关注者少、网站有问题等。
- 反方观点:无。
- 💡 对小型视觉模型的用途存在疑问。
- 解释:不清楚这种小型视觉模型有什么用途,即使能在智能手机运行,参数少是否影响识别能力。
- 💡 对3B模型的性能表示好奇。
- 解释:询问3B模型的情况,并认为比2B模型性能好是合理的。
- 💡 对模型是否有对应的论文及训练数据集感兴趣。
- 解释:希望通过这两个方面探究模型的可靠性与科学性。
金句与有趣评论
- “🤔 Is there a paper. What datasets was it trained on.”
- 亮点:直接体现对模型技术背景的关注。
- “👀 This is FAKE, claims to have been built with “Standford”… Reddit user has no history and HF shows the provider has no history. No papers… sketchy.”
- 亮点:概括性地指出模型可疑的原因。
- “😂 What is such a small vision model for?”
- 亮点:简单直接地提出对小型视觉模型用途的疑问。
- “💡 It is amazing performance.”
- 亮点:简洁表达对模型性能的肯定。
- “😕 I understood that they are capable of being run in theory on smartphones, but if they don’t have many parameters, what would be their ability to recognize anything?”
- 亮点:深入探讨小型视觉模型在智能手机上运行时参数与识别能力的关系。
情感分析
总体情感倾向较为中性,有积极肯定模型性能的,也有质疑模型真假的。主要分歧点在于模型的真实性,可能的原因是模型缺乏相关的证明资料(如论文)以及发布者相关信息存在疑点等。
趋势与预测
- 新兴话题:在不同手机上运行模型的差异可能会引发后续讨论。
- 潜在影响:如果模型是真实有效的,可能会对边缘设备上的人工智能应用产生推动作用;如果模型是假的,可能会引发对模型发布审核机制的关注。
详细内容:
标题:CMU 和斯坦福发布强大的 3B 视觉语言模型引发 Reddit 热议
近日,Reddit 上一则关于“CMU 和斯坦福发布强大的 3B 视觉语言模型 Ivy-VL”的帖子引起了广泛关注。该帖子介绍了 Ivy-VL 是一款只有 3B 参数的轻量级多模态模型,能接受图像和文本输入并生成文本输出。因其轻量设计,可部署在边缘设备如 AI 眼镜和智能手机上,内存占用低且速度快,在多模态任务上表现出色。帖子还提供了相关模型的链接,如https://huggingface.co/AI-Safeguard/Ivy-VL-llava 。此帖获得了众多点赞和大量评论。
讨论主要集中在以下几个方面: 有人询问是否有相关论文以及模型是基于哪些数据集训练的。 有用户质疑这么小的视觉模型有何用途,有人回应称可在显存有限的设备如手机、笔记本上运行,且小模型更易于微调,能促进更快的创新。但也有人表示理解其理论上能在智能手机运行,但因参数少担心识别能力。 有人认为该模型声称来自斯坦福的说法存疑,比如提供者在 Reddit 上无历史记录,相关网站和社交媒体账号也存在诸多问题。 关于模型的大小和性能,有人指出该模型号称 3B 但实际参数为 3.8B,比 2B 模型大,质疑其是否真能在边缘设备运行,也有人分享自己在手机上运行较大模型的经历。
有用户分享道:“我使用 Redmagic 8s pro 16gb 手机,运行了 Deepseek v2 Lite、Yi 9B 200k 微调、Hermes Llama 3 8b 以及一些 Mistral 微调。我通常选择 q4_0_4_8 量化。我使用的是 ChatterUI 应用。”
讨论中的共识在于对模型的实际性能和应用场景存在一定的疑问和争议。特别有见地的观点如认为小模型的优势在于易于在有限资源设备上运行和便于微调创新。
总体而言,这次关于 CMU 和斯坦福发布的 3B 视觉语言模型的讨论,展现了大家对新技术的关注和审慎态度。


感谢您的耐心阅读!来选个表情,或者留个评论吧!