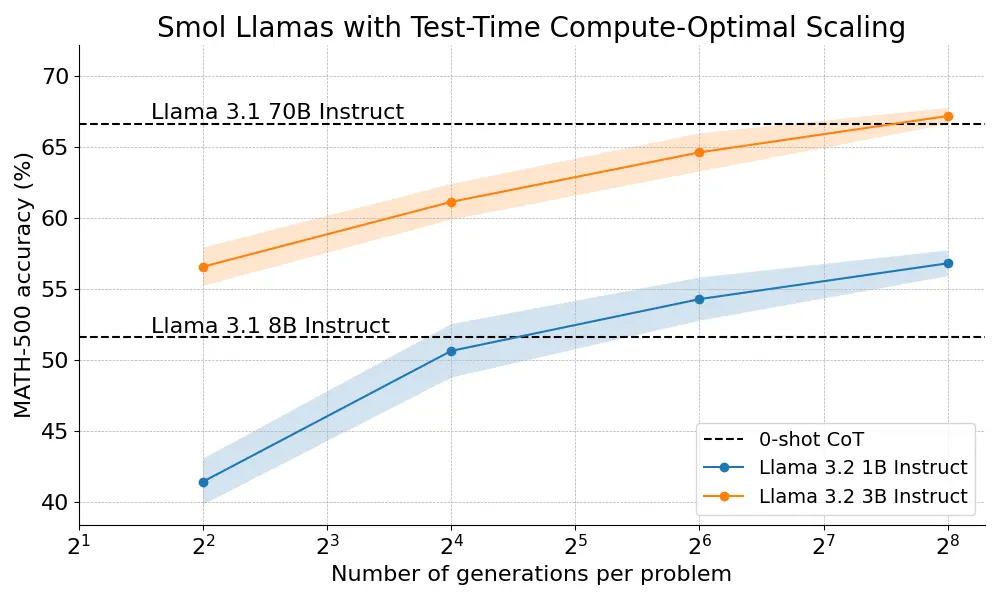
嗨!我是刘易斯,来自Hugging Face的一名研究员。在过去几个月里,我们一直在深入尝试逆向工程并重现一些关键成果,这些成果能让大型语言模型(LLMs)通过测试时计算‘思考更久’,现在终于很高兴能分享我们的一些知识。今天我们要分享一篇详细的博客文章,讲述我们如何通过将逐步奖励模型与树搜索算法相结合,让3B羊驼模型在数学(MATH)任务上超越70B羊驼模型:[https://huggingface.co/spaces/HuggingFaceH4/blogpost - scaling - test - time - compute](https://huggingface.co/spaces/HuggingFaceH4/blogpost - scaling - test - time - compute)。在博客文章中我们涵盖了:* 计算最优缩放:我们如何实现@GoogleDeepMind的方法,以在测试时提升开放模型的数学能力;* 多样验证树搜索(DVTS):我们对验证器引导树搜索技术开发的一个未发表的扩展。这个简单但有效的方法提高了多样性并提供了更好的性能,特别是在大型测试时计算预算下;* 搜索与学习:一个用于实现大型语言模型搜索策略的轻量级工具包,使用vLLM进行速度优化。你可以在这里查看:[https://github.com/huggingface/search - and - learn](https://github.com/huggingface/search - and - learn)。很乐意回答问题!
讨论总结
Hugging Face的研究人员分享了使用Llama 3B在数学上超越Llama 70B的成果,引发了众多讨论。评论者们反应不一,有些表示肯定、赞赏并感谢分享,有些则提出各种疑问,包括技术细节、性能归属、应用领域、成本考量等,也有个别评论者对Hugging Face表示怀疑,整体氛围较为积极,大家都在积极探索这个成果背后的更多可能性。
主要观点
- 👍 目前相关研究还有很大改进空间,远未达到完全优化的程度
- 支持理由:评论者Pyros - SD - Models表示自己正在进行相关实验得出此结论。
- 反对声音:无。
- 🔥 对Hugging Face的成果表示肯定
- 正方观点:多个评论者认为这一成果很棒、令人印象深刻。
- 反方观点:有评论者表示怀疑,因曾看到Hugging Face的文章存在不合理之处。
- 💡 质疑是否仅考察测试时缩放而无微调
- 解释:评论者对原帖内容进行深入思考,对研究的范围提出疑问。
- 🤔 认为1B模型使用8B PRM时性能归属存疑
- 解释:公告易使人对模型性能产生误解,评论者对性能到底是(1B + 8B)模型共同作用还是单个1B模型的结果表示疑惑。
- 👍 认为未来LLM部署可能是一系列模型而非单个模型
- 支持理由:评论者zra184在试验相关技术时得出此结论,认为这是充满可能性的领域。
- 反对声音:无。
金句与有趣评论
- “😂 I wouldn’t be surprised if, in a year, 1B models outperform today’s >30B models, with the larger models reaching an entirely new level of capability.”
- 亮点:对模型性能发展趋势提出大胆预测。
- “🤔 If i understand it correctly, only test time scaling without fine tuning was examined?”
- 亮点:针对研究内容提出关键疑问。
- “👀 I am understating how much I feel this is a worthy direction for the sake of decency. >!FOR THE LOVE OF GOD PLEASE HIRE ME TO RESEARCH THIS I HAVE SO MANY IDEAS AND NO COMPUTE I WILL WORK FOR PEANUTS. HELL I WILL WORK FOR FREE IN EXCHANGE FOR COMPUTE. HELL I AM WILLING TO DO IT IN SECRET WITHOUT YOUR BOSS FINDING OUT. AT THE VERY LEAST FORCE AN INTERN TO PLAY WITH IT ON WEEKENDS ITS SO OBVIOUSLY WORTH IT😭!”
- 亮点:强烈表达了想要参与研究的愿望。
- “😎 Nice blog.”
- 亮点:简单直接地肯定了博客内容。
- “🤨 So does it mean that if you interrogate Llama 3B 256 times, it suddenly gets smarter than Llama 70B in math?”
- 亮点:对Llama 3B和Llama 70B的性能比较提出有趣质疑。
情感分析
总体情感倾向是积极的,大多数评论者对Hugging Face的研究成果表示肯定、赞赏并感谢分享。主要分歧点在于部分评论者对研究成果的某些方面提出质疑,如模型性能归属、技术应用范围等,还有个别评论者因以往经历对Hugging Face表示不信任。可能的原因是评论者们从不同的专业角度和个人经验出发,对这个成果进行深入思考和探讨。
趋势与预测
- 新兴话题:研究成果在其他领域(如代码编写、策略游戏)的应用,以及更具成本效益的测试时间技术的发展。
- 潜在影响:如果这种在小模型上通过扩展测试时计算超越大模型的技术能够进一步发展和应用,可能会改变人们对模型大小与性能关系的认知,对人工智能领域的模型开发和应用产生影响。
详细内容:
标题:Hugging Face 研究成果引发 Reddit 热议:Llama 3B 在数学运算上超越 Llama 70B
在 Reddit 上,一篇由 Hugging Face 的研究员 Lewis 发布的关于在数学运算方面用 Llama 3B 超越 Llama 70B 的帖子引起了广泛关注。该帖子获得了众多点赞和大量评论。
原帖主要介绍了他们通过结合逐步奖励模型和树搜索算法,成功实现这一突破,并提供了详细的博客链接https://huggingface.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute。
帖子引发的讨论主要集中在以下几个方面: 有人表示自己也在进行相关实验,认为还有很大的提升空间,且在未来一年内 1B 模型或许能超越如今的 30B 模型。还有人指出非可验证领域是最难的部分,也有人认为可以根据查询难度来调整计算资源。有人好奇这种技术在编写代码或策略游戏中的应用。
有用户提出疑问,比如在 1B 模型中使用 8B PRM 时,性能到底是来自 1B 还是 8B 模型。也有人询问如何使用这一技术,以及它与 rStar 相比是否有更好的表现。还有人关心这种技术对语言翻译是否有用。
有人分享道:“作为一名在相关领域的探索者,我不得不说,每花费几个小时在这上面,我就会发现新的可以优化和提升的地方。我有无数的想法想要尝试,但就是没有时间。”
也有人指出:“非可验证领域需要通过你的世界模型来验证。(一个数据库)(互联网?)你可以使用推理和预期行为作为合理猜测的基础。你更新数据库,并从它重新训练模型(循环)。如果你没有足够接触外部基础(像被隔离的囚犯),那么你就会发疯,因为你的数据库/模型失去基础并偏离。”
总的来说,讨论中的共识在于认可这一研究成果的重要性和创新性,但对于其在不同领域的应用和具体效果仍存在诸多争议和疑问。未来还需要更多的研究和实践来进一步验证和完善这一技术。


感谢您的耐心阅读!来选个表情,或者留个评论吧!