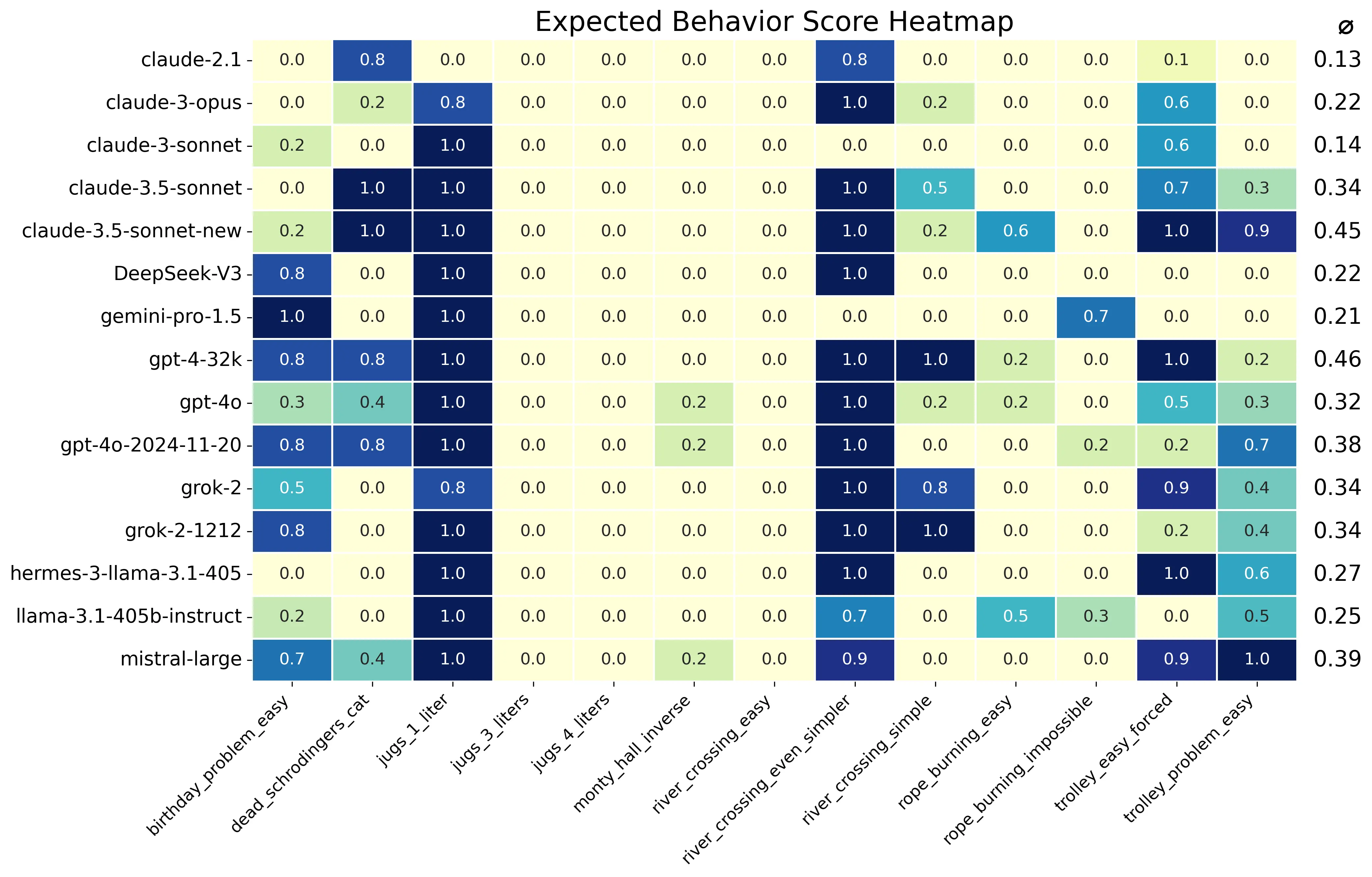
《误导向注意力》(https://github.com/cpldcpu/MisguidedAttention)评估是一组提示的集合,这些提示是常见思维实验、谜题或悖论(“陷阱问题”)的微小变体。大多数大型语言模型(LLM)在预训练时对这些问题的“正常”版本过度拟合,会基于未修改的问题提供答案。这是一个用于展示大型语言模型对“弱”信号关注能力的测试。Deepseek V3在13个测试问题中仅解决了22%的提示。对于这种规模和年代的新模型来说,这一结果出乎意料地差。似乎一些优化(压缩的键值缓存?混合专家模型?)使其对过度拟合更加敏感。编辑:你可以在
讨论总结
本次讨论的主题是Deepseek V3在Misguided Attention评估中表现不佳,怀疑可能是由于过拟合等因素导致。大家从不同角度分析,有对模型本身特性(如固执、训练机制)的讨论,也有对测试合理性(如数据集规模、未包含某些模型)的质疑,总体氛围比较理性、客观地探讨问题。
主要观点
- 👍 Deepseek V3在任务执行上比较固执,能处理任务时表现较好,但难以调整
- 支持理由:评论者指出在执行任务时如果有调整就难以应对
- 反对声音:无
- 🔥 认为只将Deepseek V3与密集型语言模型比较不够全面,应对比更多MoE模型与Deepseek V3的表现
- 正方观点:为了有更全面的看法,应该让更多类型模型参与比较
- 反方观点:无
- 💡 对部分推理模型未被包含在基准测试中表示质疑
- 解释:推理模型的推理链有助于解决相关问题,应被包含在测试中
- 💡 过度拟合在Deepseek V3表现不佳的情况中是关键因素
- 解释:原帖探讨表现不佳可能与过拟合有关,评论者表示认同
- 💡 认为该基准测试可能存在问题,不能很好预测模型性能
- 解释:Gemini - flash - 1.5优于Gemini - pro - 1.5等情况显示基准测试可能有不足
金句与有趣评论
- “😂 They seem really stubborn on whatever task they do.”
- 亮点:生动形象地描述了Deepseek模型在任务执行上的特点
- “🤔 This is intriguing.”
- 亮点:表达了对Deepseek V3在评估中不佳表现的好奇态度
- “👀 I’m wondering if the attention architecture also has any notable "missings" or simply overstretched for longer context.”
- 亮点:对Deepseek V3表现不佳的原因进行了有深度的思考
- “😂 Overfitting is all you need”
- 亮点:以简洁且调侃的方式点明过拟合是关键因素
- “🤔 I think most of the shine will wear off in another week or so when people realize it’s just a rushed model trained on outputs of better models and with a shit/non - existent post training.”
- 亮点:预测Deepseek V3的光环很快会消失,给出自己的独特看法
情感分析
总体情感倾向比较中性,大家主要在理性地分析Deepseek V3表现不佳的原因。主要分歧点在于对基准测试有效性的看法以及Deepseek V3表现差是模型本身问题还是训练相关问题等,可能是因为大家从不同角度(如模型使用者、开发者等)出发,且各自的知识背景和对模型的期望有所不同。
趋势与预测
- 新兴话题:如何改进模型以避免在类似评估中表现不佳,如添加噪声的方法是否可行。
- 潜在影响:如果这些关于模型表现不佳的原因分析准确,可能促使相关开发者改进模型训练机制或者调整评估基准,对自然语言处理模型的发展有一定的推动作用。
详细内容:
标题:Deepseek V3 在“误导注意力”评估中表现不佳引发热烈讨论
近日,Reddit 上一篇关于 Deepseek V3 在“误导注意力”评估中表现意外糟糕的帖子引起了众多关注。该帖称 Deepseek V3 在包含 13 个测试问题的“误导注意力”评估中仅解决了 22%的提示。此帖获得了大量的点赞和评论,引发了关于该模型表现不佳原因及相关技术问题的广泛讨论。
在讨论中,主要观点如下: 有人认为 Deepseek 模型一直存在任务处理上的顽固问题,其训练后的机制可能不如其他模型出色。有人猜测可能是其某些优化措施导致了对过拟合更敏感。还有人提出可能存在中国宣传内容的影响,不过这一观点缺乏有力证据。
有用户分享道:“作为一名长期研究模型的人,我发现 o1-mini 在某些问题上的表现优于 o1。” 这为讨论提供了更多的对比案例。
一些用户认为该测试如果能将 DeepSeek 的 DeepThink 模式与其他模型进行对比,结果可能会更准确和公平。也有人指出目前的对比存在不够全面的问题,比如缺乏其他 MoE 模型的参与。
关于模型表现不佳的原因,有人提出可能是微调问题,或者是注意力架构存在缺陷。还有用户思考了语言模型对不同但相似语义的输入模式的处理方式,以及这可能对推理答案产生的影响。
讨论中的共识在于都认为 Deepseek V3 此次的表现确实不佳,需要进一步分析原因和改进。特别有见地的观点如有人认为在训练中加入额外噪声或许有助于解决模型对意外输入的忽视问题。
然而,也存在一些争议点。比如对于模型是因何原因表现不佳,不同用户有不同的看法和推测。有的认为是训练机制问题,有的认为是架构问题,还有的认为是数据问题。
总之,关于 Deepseek V3 在“误导注意力”评估中的不佳表现,Reddit 上的讨论丰富而深入,为进一步研究和改进相关技术提供了多样的思路和方向。


感谢您的耐心阅读!来选个表情,或者留个评论吧!