今天我们发布了
讨论总结
这是关于SmallThinker - 3B - Preview发布的讨论。大部分人对模型发布表示认可和赞赏,讨论涉及模型微调工具、训练细节、作为草稿模型的使用、在不同设备上的运行、推测解码功能等技术方面,也有对模型表现提出疑问或指出局限性的,还有少量负面评价。
主要观点
- 👍 对SmallThinker - 3B - Preview的发布表示认可和赞赏
- 支持理由:很多评论者直接表达模型很酷、很棒等积极态度。
- 反对声音:有评论者提到“ugh, token barf”表达负面态度。
- 🔥 模型在技术方面有很多值得探讨之处
- 正方观点:例如模型微调、训练运行、在不同设备上的操作等技术细节有很多人关注。
- 反方观点:无明显反对观点。
- 💡 较小模型存在很大潜力
- 解释:有评论者指出小模型在消费级GPU上运行速度快、在相同显存下可添加更多上下文等优势。
- 💡 模型存在一些局限性
- 解释:如模型会产生重复输出、回答可能随机、在特定参数设置下会回答失败等。
- 💡 模型在特定任务上有不同表现
- 解释:例如在回答“香蕉盘子”问题时受温度、重复惩罚等参数影响。
金句与有趣评论
- “😂 This is cool, I’ve been looking for something like this.”
- 亮点:简洁地表达对模型发布的积极态度和兴趣。
- “🤔 This is awesome. What tools did you use to fine tune this model?”
- 亮点:引出模型微调工具的讨论。
- “👀 Can you perhaps give more details of this training run?”
- 亮点:关注模型训练运行细节。
- “😂 I set max tokens to 8000, but I see that in many cases it does not stop yet and it keeps iterating. What is a sensible upper limit?”
- 亮点:提出关于模型设置时遇到的实际问题。
- “🤔 One question: how did you verify the data, if at all? (from my experience) Models trained on this type of data tend to "learn" to make mistakes.”
- 亮点:对模型数据验证提出怀疑。
情感分析
总体情感倾向是积极的,大部分评论者认可模型发布。主要分歧点在于对模型输出质量的看法,如有的评论者觉得模型很棒,而有的评论者用“ugh, token barf”表示不满。可能的原因是不同用户对模型的期望不同,以及在不同应用场景下对模型表现的体验有所差异。
趋势与预测
- 新兴话题:对更小QwQ模型发布的期待,以及希望看到专门训练使用RAG和工具的小型推理模型。
- 潜在影响:如果这些小型推理模型发展良好,可能会推动边缘计算等相关领域的发展,并且改变人们对模型推理能力与模型规模关系的认知。
详细内容:
标题:SmallThinker-3B-Preview 模型在 Reddit 引发热烈讨论
近日,Reddit 上一篇关于“Introducing SmallThinker-3B-Preview. An o1-like reasoning SLM!”的帖子引发了众多关注。该帖子介绍了 SmallThinker-3B-Preview 模型,获得了大量的点赞和众多评论。
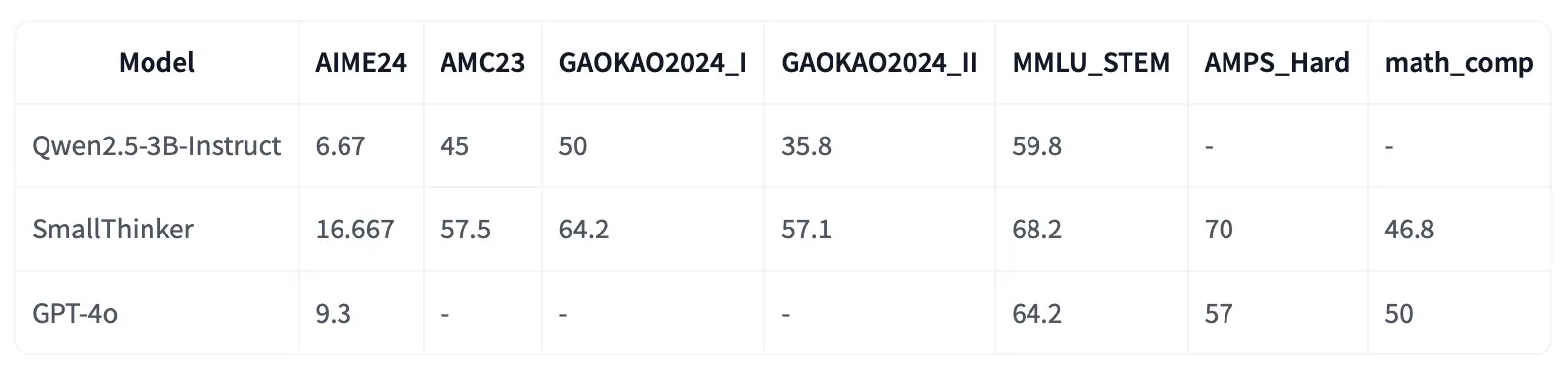
帖子主要内容包括模型的发布链接SmallThinker-3B-Preview,它是从Qwen2.5-3b-Instruct微调而来。还提到了模型在 NVIDIA-2080Ti 上的运行情况以及基准分数。该模型适用于边缘部署,可作为更大模型的快速高效草案模型,在 llama.cpp 中能实现速度提升。同时也公开了用于训练的数据集,并指出了模型目前存在的重复输出等问题。
讨论焦点主要集中在以下几个方面: 有人称赞这个模型很酷很厉害,比如有人说:“这太棒了,我一直在寻找这样的东西。” 也有人询问微调模型所使用的工具,有人回答:“我们利用了 llama-factory!” 还有人希望了解更多训练运行的细节,比如:“能提供更多此次训练运行的细节吗?” 对于模型的微调所需的 GPU 数量也有人提出疑问。
关于模型与其他框架的比较和适用性也引发了热烈讨论。有人认为在小数据集上,LoRA 可能更好,但也有人认为在大规模数据集上,FFT 能提供更全面的模型。 有人提到:“在我的大量测试中,FFT 将提供一个更全面的模型,特别是在像 Instruct FFT -> RP FFT - > RL FFT 这样的分层结构中应用时。”
在模型的应用和性能方面,有人分享了自己尝试后的经历:“我刚试过,它生成的答案非常随机,即使在最终答案之后还在继续。” 有人探讨模型在理解和处理网络内容方面的能力,认为较小的模型在这方面存在缺乏上下文的问题。
总的来说,Reddit 上关于 SmallThinker-3B-Preview 模型的讨论丰富多样,既有对其创新和优势的肯定,也有对其存在问题和改进方向的思考。未来,我们期待看到这个模型的不断完善和更广泛的应用。


感谢您的耐心阅读!来选个表情,或者留个评论吧!