X: [https://x.com/NovaSkyAI/status/1877793041957933347] hf: [https://huggingface.co/NovaSky - AI/Sky - T1 - 32B - Preview] blog: [https://novasky - ai.github.io/posts/sky - t1/]
讨论总结
[本讨论主要围绕Sky - T1 - 32B - Preview开源推理模型展开。部分人对该模型的成果表示赞赏,认为是了不起的贡献,模型性能不错等;然而也有很多人表示怀疑,怀疑其是否“好得令人难以置信”、是否过度训练、实际使用体验是否糟糕等,同时还涉及模型相关概念如训练与微调的争议等内容]
主要观点
- 👍 认为Sky - T1 - 32B - Preview模型的数据、代码和模型权重是了不起的贡献
- 支持理由:未明确提及,但从表述来看是认可模型在这些方面有一定成果或意义。
- 反对声音:无。
- 🔥 对Sky - T1 - 32B - Preview模型的成果表示怀疑
- 正方观点:模型可能存在“好得令人难以置信”的情况,之前有低成本训练但效果不佳的模型。
- 反方观点:部分人认为模型表现不错,如在基准测试和特定测试中有较好结果。
- 💡 认为模型需达到一定大小才能使思维链可行
- 解释:以小模型训练改进效果有限、输出存在重复内容为例,说明模型大小的重要性。
- 💡 反对用“训练”代替“微调”这种误导性表述
- 解释:在当前LLM状况下几百美元训练一个模型是不可能的,微调比训练更符合实际情况。
- 💡 对Sky - T1 - 32B - Preview模型进行了基准测试且结果不错
- 解释:测试结果在不同关系下大多为100.00,没有思想循环的问题。
金句与有趣评论
- “😂 Data, code and model weights - what an amazing contribution.”
- 亮点:简洁地概括了对模型几个重要方面的肯定。
- “🤔 Is this a too good to be true situation?”
- 亮点:直接表达出对模型的怀疑态度。
- “👀 Model size matters.”
- 亮点:明确提出模型大小在模型有效性方面的重要性。
- “😂 There is no moat.”
- 亮点:表达出在AI领域没有难以逾越的障碍的观点。
- “🤔 its qwen, but worse”
- 亮点:简单直接地对Sky - T1 - 32B - Preview模型与Qwen进行对比评价。
情感分析
[总体情感倾向比较复杂,既有正面积极的情感,如对模型表示赞赏、期待等;也有负面消极的情感,如怀疑、反对等。主要分歧点在于模型的实际成果、是否过度训练、与其他模型对比结果等方面。可能的原因是大家对模型的评估标准不同,以及对模型的训练方式、性能表现等方面有不同的理解]
趋势与预测
- 新兴话题:[模型的商业用途可行性可能会引发更多讨论,还有模型的GGUF化操作及相关量化内容]
- 潜在影响:[如果模型的商业用途可行,可能会对相关行业产生影响;如果模型在测试和实际应用中表现稳定良好,可能会影响人们对开源推理模型的看法]
详细内容:
标题:关于 Sky-T1-32B-Preview 模型的热门讨论
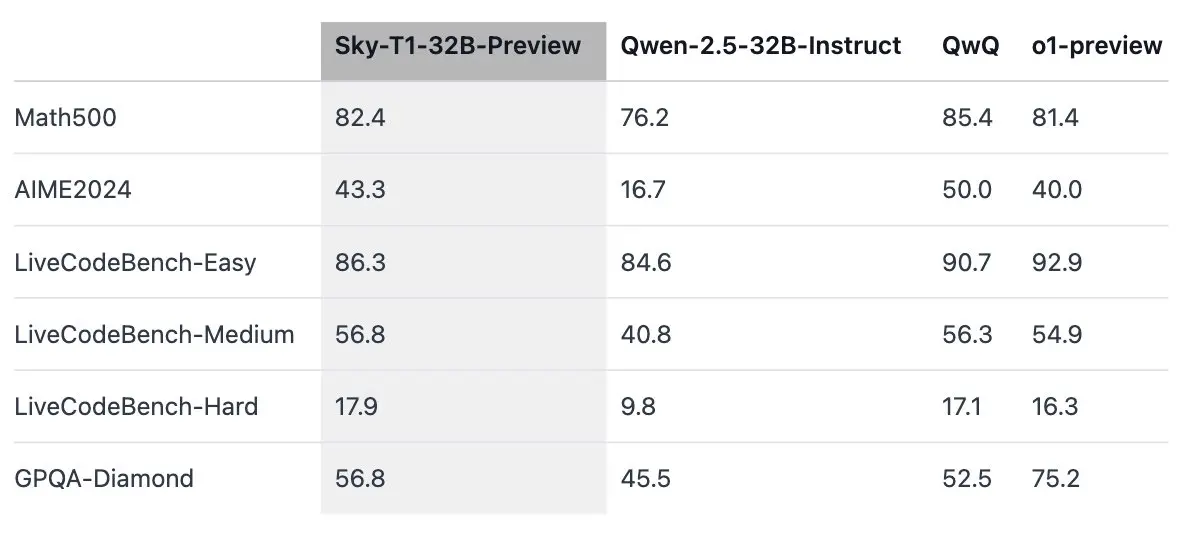
近日,Reddit 上一则有关新型开源推理模型 Sky-T1-32B-Preview 的帖子引发了热烈关注。该帖获得了众多点赞和大量评论。原帖提供了多个相关链接,包括模型的介绍和技术细节等。帖子主要探讨了这个模型在流行推理和编码基准上的表现,且声称其训练成本仅为 450 美元。
这一话题引发了诸多讨论焦点和不同观点。有人称赞这是一项惊人的贡献,数据、代码和模型权重的公开令人欣喜。但也有人质疑其真实性,认为这可能好得难以置信,需要进一步测试。还有人认为该模型可能存在过度训练的问题。
有用户分享道:“我们最初在较小的模型(7B 和 14B)上进行训练实验,仅观察到了适度的改进。例如,训练 Qwen2.5-14B-Coder-Instruct 在 APPs 数据集上,LiveCodeBench 的性能从 42.6%略微提升到 46.3%。然而,手动检查较小模型(小于 32B)的输出时,发现它们经常生成重复内容,限制了其有效性。”
有人提出有趣的观点,将大型语言模型比作“一个读过整个互联网的疯子”,认为模型规模越大,知识储备越丰富,对解决问题越有帮助。但也有人认为,真正的通用人工智能可能需要 1T 以上参数的模型,但目前在硬件和成本方面还不现实。
对于模型的训练和微调,也存在争议。有人认为用“训练成本仅 50 美元”这样的表述具有误导性,应该明确是微调,因为这两个概念存在差异。但也有人认为这些概念本质相同,无需过于区分。
还有用户在测试该模型后,认为其在数学和编码方面表现较好,但在其他方面表现不佳。也有人指出,用密码测试模型的实用性存疑,应该测试更实际有用的领域。
总之,关于 Sky-T1-32B-Preview 模型的讨论展现了观点的多样性和复杂性。一方面,人们对其开源和低成本训练表示期待;另一方面,也对其真实性能和应用范围存在诸多疑问和思考。未来还需更多的实践和验证来明确其价值和潜力。


感谢您的耐心阅读!来选个表情,或者留个评论吧!