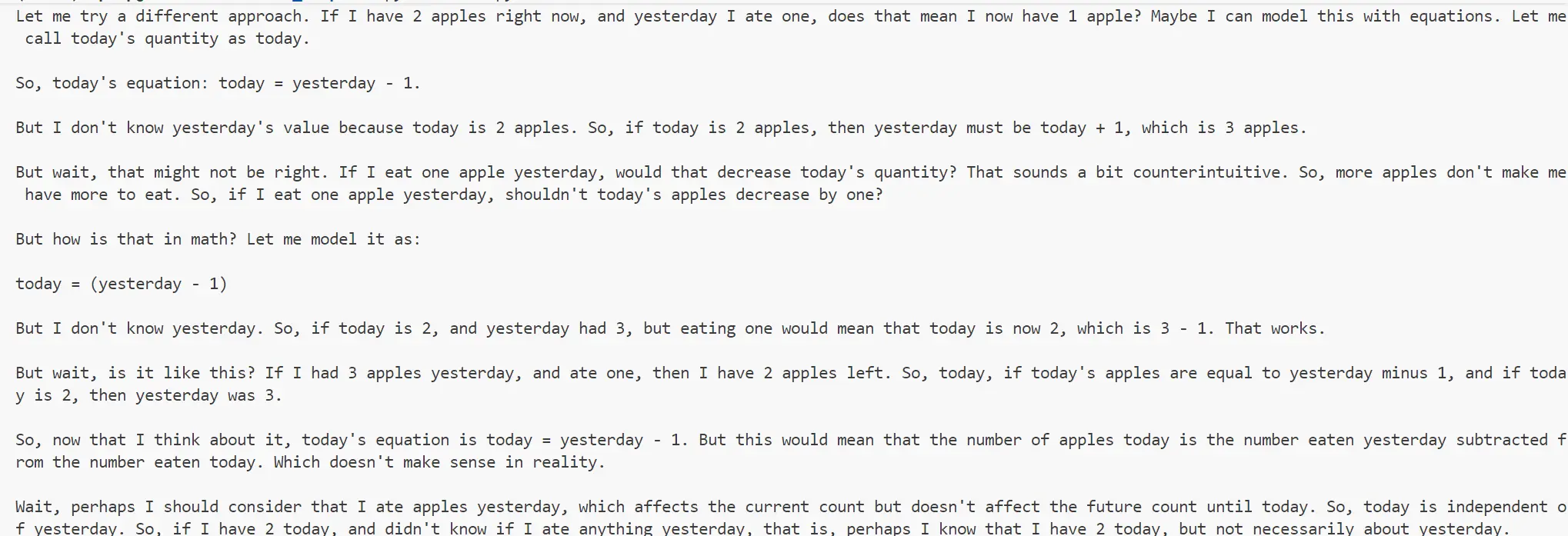
这篇文章讲述了我让DeepSeek - R1 - Distill - Qwen - 1.5B - Q4_K_M.gguf正确回答以下提示的历程:‘我现在有2个苹果,昨天吃了1个,现在我有多少个苹果?逐步思考。’ 背景:过去我通过查看logits注意到(https://www.reddit.com/r/LocalLLaMA/comments/1g7dq8s/interactive_next_token_selection_from_top_k/),如果在某些关键时刻得到正确引导,Llama 3B Q3 GGUF应该能够正确回答这个提示。随着DeepSeek模型的发布,现在我有了一个新的实验对象,因为这些模型是用某些特定短语(如‘Hmm’、‘Wait’、‘So’、‘Alternatively’)进行训练以增强推理能力的。Vgel制作了一个要点,其中将替换为其中一个这样的短语以扩展推理轨迹。我将Vgel的想法应用到回溯采样器,并注意到即使我大量扩展推理轨迹,DeepSeek - R1 - Distill - Qwen - 1.5B - Q4_K_M.gguf也无法正确回答提示。看起来一旦它过早得出错误结论,就会开始输出其他得到相同错误结论的方式,‘Wait’这个短语并没有真正触发考虑正确答案或者考虑时间因素的视角。所以我决定不仅仅替换,也将‘So’和‘Therefore’替换为‘But let me rephrase the request to see if I missed something.’以帮助它不要过早得出错误结论。现在推理文本没问题了,但问题是它就是不停下推理。它将今天/昨天作为提示的关键元素并理解正确答案可能是‘2’,但它被这个搞糊涂了并且无法得出结论。所以我添加了另一个替换标准以加快推理:在达到1024个标记后,我想让它将‘Wait’和‘But’替换为‘\nOkay, so in conclusion’。这实际上成功了,我最终成功让一个量化的‘小’模型正确回答了那个提示,哇哦!🎉 请注意,在我的实验中,我使用的是llama.cpp Python中的标准温度(0.7)。我也试过使用非常低的温度,但模型不能提供良好的推理轨迹并且开始重复自身。添加重复惩罚也会破坏输出,因为模型往往会重复某些短语。总的来说,我觉得0.7的温度就可以,因为推理轨迹很长,给了模型很多发现正确答案的机会。我提出的替换方法经过多次试验似乎效果最好,不过我确实认为替换短语可以进一步改进以更频繁地得到正确结果。
讨论总结
原帖讲述了在改善DeepSeek - R1 - Distill - Qwen - 1.5B - Q4_K_M.gguf模型回答特定提示的推理轨迹过程中的尝试与成果。评论者们围绕此展开多方面讨论,包括代码分享、对模型参数(如量化版本、温度等)的疑问与建议、对原帖采用策略有效性的质疑与新的实验建议、相关技术资源分享以及一些模型使用中的特殊情况等,整体氛围以理性探讨为主。
主要观点
- 👍 原帖通过简单方式让小模型得出正确结果值得肯定
- 支持理由:原帖作者通过多种替换操作让小模型能正确回答问题,是有趣的成就。
- 反对声音:无
- 🔥 对原帖使用Q4_K_M而非Q8表示疑惑并寻求解释
- 正方观点:不同量化版本可能影响模型性能,想知道选择Q4的原因。
- 反方观点:原帖作者基于如果小模型可行则更高量化版本会更好的假设选择Q4。
- 💡 难以判定原帖多种策略中特定策略的有效性
- 解释:原帖采用多种策略,难以确定是“okay, so in conclusion”的截断策略起了作用。
- 💡 存在为任意模型模拟类似R1推理链的可能
- 解释:评论者给出网址表明可以为任意模型模拟类似推理链。
- 💡 认为“Think step by step”可能对结果有负面影响
- 解释:这部分内容可能对结果的损害大于帮助。
金句与有趣评论
- “😂那是一个有趣的成就,仅仅通过一种相当简单的方式让这个小模型更好地思考从而得到正确的结果。”
- 亮点:肯定原帖让小模型得出正确结果的做法。
- “🤔我想要尝试一个带有Q4的小模型,基于这样一个假设:如果我能让它在这样一个模型上工作,那么那些没有被高度量化的版本将会表现得更好。”
- 亮点:解释选择Q4版本的假设依据。
- “👀你采用多种策略,很难说“okay, so in conclusion”的截断策略是起作用的那个。”
- 亮点:对原帖策略有效性提出质疑。
- “😎One can also emulate an R1 - like reasoning chain for arbitrary models:https://github.com/av/harbor/blob/main/boost/src/custom_modules/r0.py”
- 亮点:分享为任意模型模拟推理链的资源。
- “🤨Have you tried removing "Think step by step" from the prompt? It might be harming it more than helping”
- 亮点:提出对结果可能有负面影响的因素。
情感分析
总体情感倾向为中性。主要分歧点在于原帖使用的模型参数(如量化版本、温度等)是否合适,以及原帖采用的策略是否有效等。可能的原因是大家从不同角度(如模型性能、结果准确性、实验科学性等)对原帖内容进行分析探讨。
趋势与预测
- 新兴话题:对模型进行unsloths无限上下文窗口和rope scaling操作的测试。
- 潜在影响:如果对这些新兴话题进行深入研究,可能有助于进一步优化模型的性能,提高模型回答的准确性,对人工智能模型开发相关领域有一定的推动作用。
详细内容:
标题:关于改进 DeepSeek R1 推理追踪的热门讨论
最近,Reddit 上有一篇关于改进“DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf”模型回答特定提示的帖子引起了广泛关注。该帖子获得了众多点赞和大量评论,主要讨论了如何让这个模型正确回答“我目前有 2 个苹果。昨天我吃了 1 个。我现在有几个苹果?请逐步思考。”这个问题。
在讨论中,有人分享了相关的代码和实验过程。有人指出这是一个有趣的成就,通过让模型以更简单的方式更好地思考,使小型模型能够得到正确结果。但也有人提出疑问,比如为什么使用 Q4_K_M 而不是 Q8 ,以及能否用特定参数重新测试以观察结果。
有人认为使用高温度有其合理性,因为模型经常改变想法,但这也增加了风险。还有人建议进行更多单独测试,比如禁止某些关键词、分别测试不同的替换策略等。也有人分享了自己模型的特殊情况,比如 32b 模型从不包含特定标签等。
这些讨论的核心问题在于如何进一步优化模型的推理过程,提高其回答的准确性和稳定性。究竟是通过调整参数、改变策略还是其他方法,目前还没有定论,但大家都在积极探索和交流。
通过这些热烈的讨论,我们可以看到大家对于改进模型推理能力的热情和努力,也期待未来能有更多有效的方法和成果出现。


感谢您的耐心阅读!来选个表情,或者留个评论吧!