无有效内容,仅为一个图片链接:
讨论总结
这个讨论主要围绕人工智能展开。从Deepseek R1 Distill Qwen 14b 8_0输入“test”的有趣反应说起,引出对AI任务最小表达阈值的思考、模型训练是否过度以及是否存在故意为高分过度调整模型的疑问,还涉及到Qwen2.5 - coder:32b的程序异常、LM Studio的信息泄露、不同模型解答谜题的对比等话题,大家以一种探讨交流的态度在分享观点。
主要观点
- 👍 Deepseek R1 Distill Qwen 14b 8_0启动后输入“test”有有趣反应
- 支持理由:评论者internetpillows分享了自己的使用经历。
- 反对声音:无。
- 🔥 模型在输入不足时会虚构问题作答
- 正方观点:internetpillows提到输入不足时它会虚构问题然后作答。
- 反方观点:无。
- 💡 思考AI任务最小表达阈值
- 解释:Hanthunius由相关现象引发了对AI任务最小表达阈值的思考。
- 💡 怀疑模型在特定问题上过度训练易产生幻觉
- 解释:“NO_LOADED_VERSION”和“internetpillows”推测模型可能在特定问题上过度训练从而容易产生幻觉。
- 💡 某模型在解决特定谜题时表现不佳
- 解释:dpat75讲述了某模型在解答农民过河谜题时的糟糕表现。
金句与有趣评论
- “😂 Deepseek R1 Distill Qwen 14b 8_0, literally just fired it up and wrote test in a blank chat.”
- 亮点:生动描述了对模型的测试起始操作。
- “🤔 Makes me think what is the threshold of what is the minimum expression of a task where the AI doesn’t need to extrapolate and hallucinate stuff up.”
- 亮点:提出了一个关于AI任务的深度思考点。
- “👀 probably one of the repeated test questions it was trained on.”
- 亮点:对模型出现现象的一种合理推测。
- “😎 I asked Qwen2.5 - coder:32b to make a 2d physics game, which it did, but after that it kept going in Chinese, making something like "MiniFacebook" with React/mongodb.”
- 亮点:描述了程序出现的异常有趣现象。
- “🤯 我让相同的模型解决农民过河的谜题,带着狐狸和干草,它输出1000行废话,还改概念,答案还错,微软Copilot答对了。”
- 亮点:鲜明对比了不同模型解答谜题的结果。
情感分析
总体情感倾向为中性探讨。主要分歧点在于对模型表现不佳是训练问题还是本身特性的看法。可能的原因是大家对不同模型的了解程度和使用经验不同,以及对模型训练机制的理解差异。
趋势与预测
- 新兴话题:对模型训练中如何避免过度训练以及如何准确测试模型的探讨可能会引发后续讨论。
- 潜在影响:如果能够深入探讨模型的这些问题,可能有助于改进人工智能模型的训练方法和提升模型的准确性,从而对人工智能领域产生积极影响。
详细内容:
标题:关于 AI 模型的热门讨论
最近,Reddit 上有一个关于 AI 模型的帖子引发了热烈讨论。该帖子主要是有人在空白聊天中输入“test”,然后观察到了一些有趣的现象。此帖获得了众多关注,评论数众多。
帖子引发的主要讨论方向集中在不同 AI 模型的表现、训练方式以及可能存在的问题。
文章将要探讨的核心问题是:在何种输入条件下,AI 模型能够避免过度推测和虚构内容。
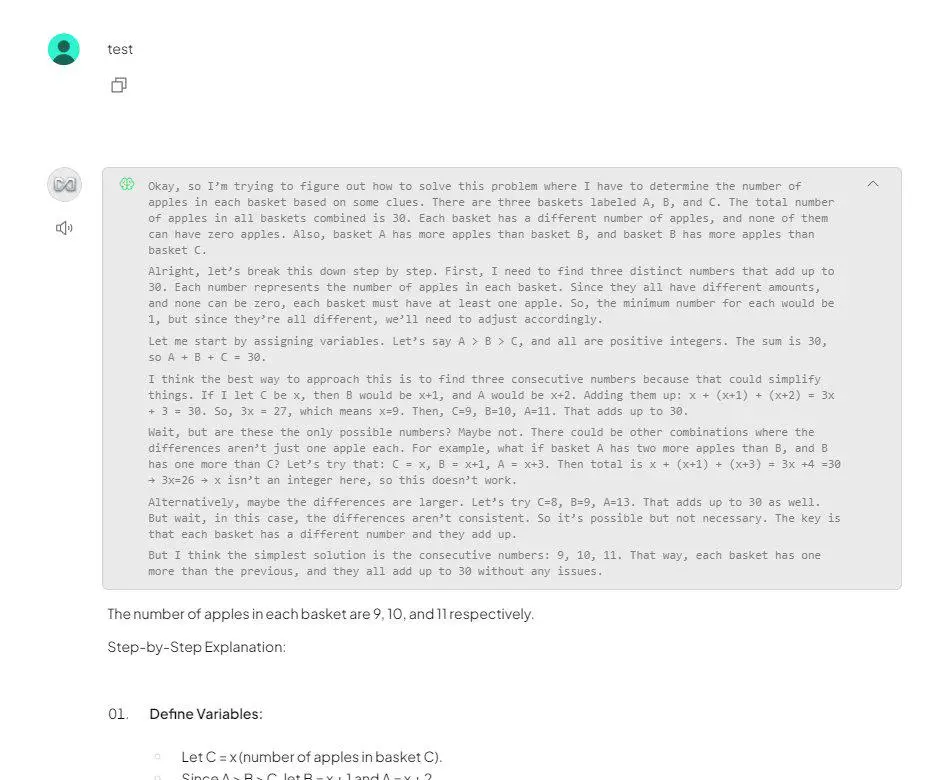
在讨论中,有人指出 Deepseek R1 Distill Qwen 14b 8_0 模型,如果输入不足,会自行虚构问题并回答,比如输入“test”时就给自己出了个临时数学考试。有人认为 R1 模型存在同样问题,需要给予强烈的系统提示来控制,否则容易出现虚构情况。还有人指出 R1 Zero 与 R1 不同,它是更具实验性的版本,训练方式有所差异。
有人分享了自己使用 AI 模型的经验,比如让 Qwen2.5 - coder:32b 制作 2D 物理游戏,结果之后出现了语言和内容上的偏差。还有人提到让同一模型解决农夫过河的谜题,结果出现错误,而微软的 Copilot 则回答正确。
讨论中的共识在于大家都关注到了 AI 模型在不同任务中的表现和可能存在的不足。特别有见地的观点如有人思考了 AI 处理任务时不需要虚构内容的输入阈值问题;还有人总结出向大型、智能的模型输入简短提示,向小型、快速的模型输入较长提示的经验。
总之,这次关于 AI 模型的讨论让我们更深入地思考了其性能和潜在问题,也为未来的研究和应用提供了更多的思考方向。


感谢您的耐心阅读!来选个表情,或者留个评论吧!