最近,我觉得用支架和转接卡连在一起的三块RTX 3090不够用;我想要一个更简洁的配置和第四块3090。为此,我需要一个新的平台。我的要求是:至少四个双倍间距的PCIe x16插槽、充足的高速存储接口,理想情况下,要有高内存带宽,以便在不降低推理速度的情况下实现一定程度的CPU卸载。英特尔新的至强系列对我没有吸引力,P/E核心设置似乎更适合数据中心,而且价格很昂贵。最初我考虑过Epyc Genoa,但随着Turin的推出及其Zen 5核心以及更高的DDR5速度,我决定直接选择它。由于SP5插座的尺寸及其12个内存通道,支持完整12通道的主板牺牲了PCIe插槽。唯一符合我PCIe要求的主板ASRock GENOAD8X - 2T/TCM只有8个DIMM插槽,这意味着我们要告别整整四个内存通道。让它启动并运行是一场冒险。当时,尽管华擎声称需要更新到10.03版(甚至还无法下载),但他们还没有发布任何与Turin兼容的BIOS ROM。他们提供的测试版ROM无法刷新,毫无缘由地失败了。最终,我不得不借助ROM编程器(CH341a)并让它在10.05版上运行起来。如果有人对主板、BIOS或设置有问题,请尽管提问,我对这块主板已经熟悉得远超自己的预期了。CPU:Epyc Turin 9355P - 32核(8个CCD),256MB缓存,3.55GHz加速到4.4GHz - 从eBay的cafe.electronics购买,价格3000美元(现在约3300美元)。内存:256GB海盗船WS(CMA256GX5M8B5600C40),频率5600MHz - 1499加元(现在约2400加元 - 搞什么鬼!)
讨论总结
原帖主要展示了Epyc Turin (9355P) + 256 GB / 5600 mhz的相关情况,包括硬件配置、基准测试结果等内容。评论从多个方面展开讨论,如希望原帖作者进行更多测试、对原帖中的测试数据提出质疑、比较原帖设备与其他设备的经济性和效率、探讨不同设备的性能等,整体氛围积极且富有技术交流氛围。
主要观点
- 👍 不同设备配置影响模型运行每秒标记数
- 支持理由:多个用户分享不同设备(如Epyc型号、内存、GPU数量不同)下的每秒标记数差异。
- 反对声音:无。
- 🔥 原帖设备在当前速度下经济性不佳
- 正方观点:设备价格高且大容量内存对大模型作用有限,相比MacBook Pro M4 Max性价比低。
- 反方观点:原帖作者给出新数据后,发现原帖设备比想象中更高效。
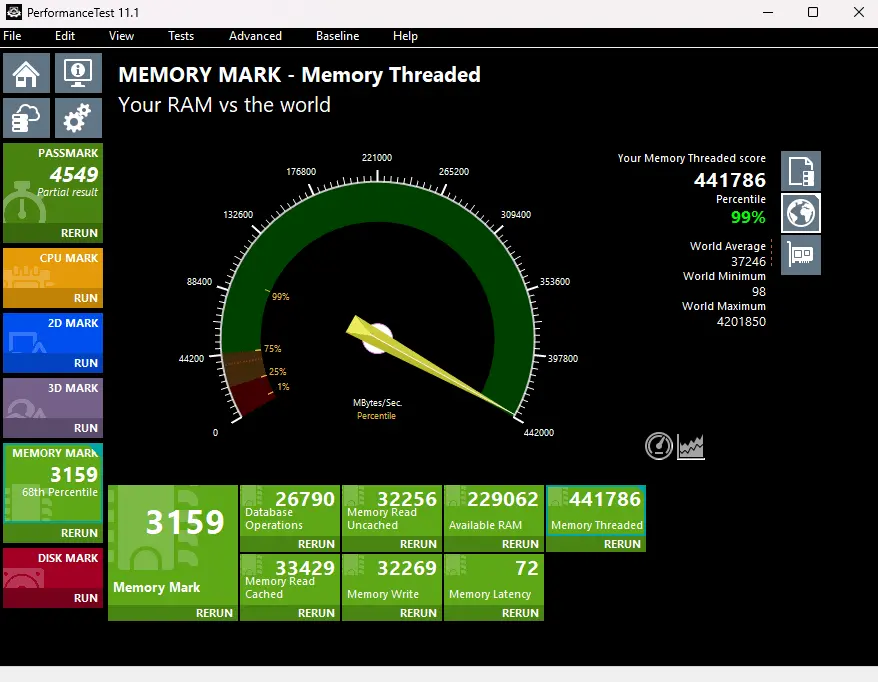
- 💡 PassMark内存线程测试数值可能高估
- 解释:理论最大值与测试显示值不符,可能误导,要求原帖补充likwid - bench测试结果。
- 🌟 原帖设备设置不错,但等待英伟达Digic更有价值
- 解释:Digic设备价格、性能、功耗有优势。
- 🤔 对原帖中的300GB/s数据表示怀疑
- 解释:评论者分享自己设备及运行结果,对比得出原帖数据偏低。
金句与有趣评论
- “😂 1.58 on Epyc 7302 + 256gb ram + 9x3090s@10k context + fully loaded into vram = 10 - 19 t/s depending on how full context is.”
- 亮点:直观展示特定设备在特定条件下的每秒标记数情况。
- “🤔 Great to see, but not that economical at these speeds, is it?”
- 亮点:简洁地对原帖设备的经济性提出疑问。
- “👀 请添加the likwid - bench内存带宽测试结果,因为PassMark以在其内存线程测试中倾向于高估数值而闻名。”
- 亮点:指出原帖测试结果可能存在的问题及解决办法。
- “💥 For the price of the rig (about $5000 US not including the 4x 3090s?), you could get a MacBook Pro M4 Max with 128GB Ram and run these models faster at a lot less power draw.”
- 亮点:通过对比突出原帖设备在经济性和效率方面的问题。
- “😎 我使用Threadripper Pro 3955w和512GB 2666MHz内存时,运行Q4 deepseek v3每秒能得到3个token,实际带宽约为90GB/s,你的数据似乎很低,所以我认为你实际上没有达到每秒300GB。”
- 亮点:用自己的设备数据质疑原帖数据。
情感分析
总体情感倾向较为积极正面,大家积极参与技术交流。主要分歧点在于对原帖设备的性能、经济性、数据准确性等方面的看法。可能的原因是不同用户有不同的设备使用经验、对性价比的衡量标准不同以及对测试数据准确性的重视程度不同。
趋势与预测
- 新兴话题:新的量化方式(如Q2_K_XL动态DeepSeek量化)可能会引发后续更多关于其性能测试的讨论。
- 潜在影响:如果CPU推理技术不断发展,可能会打破英伟达在AI硬件方面的部分垄断,改变相关市场格局。
详细内容:
标题:Epyc Turin 平台搭建与 CPU 推理性能的热门讨论
最近,Reddit 上有一篇关于使用 Epyc Turin 9355P 搭建新平台并测试其 CPU 推理性能的帖子引发了热烈讨论。该帖子获得了众多关注,评论数众多。
原帖作者表示,为了获得更清洁的设置和容纳第四块 RTX 3090 显卡,他选择了 Epyc Turin 平台。此平台满足了他对多个 PCIe x16 插槽、高速存储接口和高内存带宽的需求。但在搭建过程中遇到了 BIOS 问题,最终通过 ROM 编程器解决。作者还分享了一系列的测试结果和基准数据,并表示 CPU 推理对于较小模型较为可用,而较大模型仍依赖 GPU/云。
讨论中的焦点观点众多。有人希望作者尝试运行特定的量化模型并报告相关数据;有人对测试结果的真实性表示怀疑;还有人关注 CPU 负载情况以及提供了相关的优化建议和参考资料。
有用户分享自己使用不同 Epyc 配置的经历,如 [Murky - Ladder8684] 提到在不同 Epyc 配置下的运行效果和相关参数。也有用户对成本、能效、扩展性等方面进行了探讨。比如 [piggledy] 认为对于这些速度而言,该配置不太经济,RAM 似乎有些过剩,相比之下,MacBook Pro M4 Max 可能更具优势;[Psychological_Ear393] 则指出 Mac 的 PCIe 通道和 RAM 扩展存在限制。
在讨论中,对于 Nvidia 的新设备 Digic 的性能和带宽,大家也各抒己见。
有人认为 CPU 推理仍不可行,也有人对未来的发展保持乐观。
总之,这场关于 Epyc Turin 平台和 CPU 推理性能的讨论展示了大家在技术探索和应用中的多样观点和思考。


感谢您的耐心阅读!来选个表情,或者留个评论吧!