刚刚尝试了在X(推特)上发现的Anemll(https://github.com/Anemll/Anemll),它能让你直接在神经引擎上运行模型,与在GPU上运行的lm studio或ollama相比功耗低得多。
llama - 3.2 - 1b通过anemll和通过lm studio运行的一些结果:
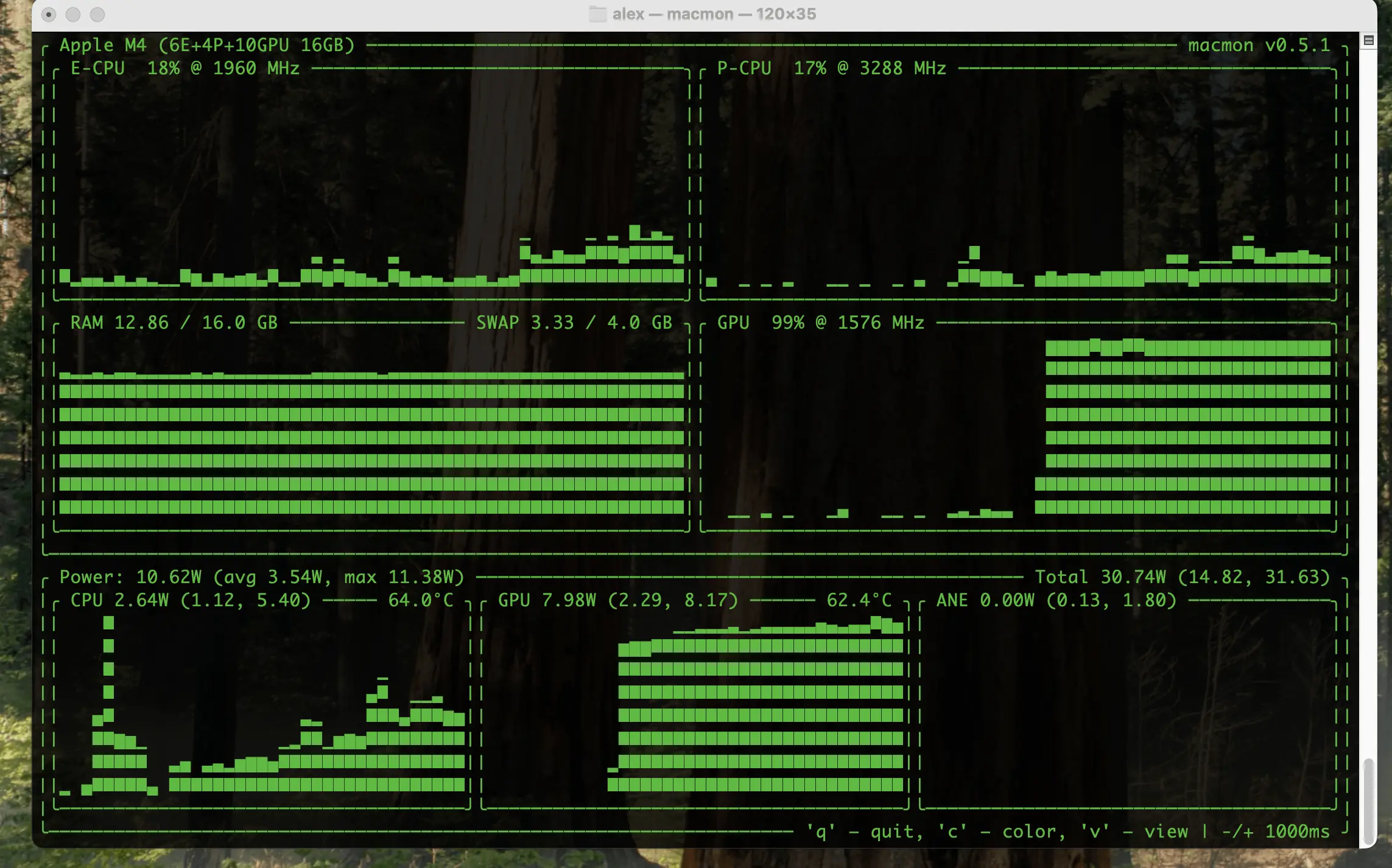
- 功耗从GPU上的8W降低到ane(神经引擎)上的1.7W。
- 每秒处理事务数(Tps)仅略有下降,从56t/s降至45t/s(但不知道anemll的量化情况,我运行的lm studio的是Q8)。
Anemll模型的上下文只有512,不确定是神经引擎的限制还是他们尚未转换更大的模型。如果你想尝试,可以前往他们的[huggingface](https://huggingface.co/collections/anemll/anemll - 011 - 67aa41b5ba1bcdd966a28fd0)并按照那里的说明操作,Anemll的git仓库设置更多,因为你必须转换自己的模型。
第一张图片是lm studio,第二张是anemll(查看右下角的功耗),第三张来自X。[通过anemll运行](https://preview.redd.it/fqoni8uec6je1.png?width = 2286&format = png&auto = webp&s = a14f2a9705151d9403b3372d0273c16b94272e0c) [效率比较(来自X)](https://preview.redd.it/0rs2603jc6je1.png?width = 3629&format = png&auto = webp&s = bb492408d21f4b064bcc8dec0d3945a736ffb4dc) 我认为这非常酷,我希望这个项目能得到更多支持,这样我们就能在上面运行更多、更大的模型!并且希望LM studio团队能很快支持这种新的模型运行方式

讨论总结
原帖介绍了能在Mac神经引擎上运行模型的Anemll项目,并给出了与其他运行方式的对比结果。评论者们从多方面进行讨论,有人提供技术补充如Anemll的量化信息,有人对在这一引擎上运行模型的意义和潜力发表看法,还有人提出疑惑如能否用于Apple Vision Pro以及Metal与神经引擎的关系等,整体氛围较为积极且对相关技术发展充满期待。
主要观点
- 👍 在Mac神经引擎运行模型可用于终端补全且对桌面无影响、电池使用可行
- 支持理由:如SporksInjected指出可以在内存中加载小模型用于终端补全,在桌面和电池使用场景都没问题。
- 反对声音:无。
- 🔥 在苹果和高通NPUs上的成功会促使更多资源投入到优化对LLMs的支持上
- 正方观点:SkyFeistyLlama8认为会吸引芯片制造商和操作系统开发者关注,从而推动发展。
- 反方观点:无。
- 💡 Anemll项目看起来很新且有前景
- 解释:评论者表示之前未见过在神经引擎上运行模型(如果之前可行的话),并看好项目前景。
- 💡 在AI领域功率消耗不是最应担忧的,期望苹果提供带宽更优芯片
- 解释:nderstand2grow从自身对人工智能关注点出发,认为相比功率消耗,带宽更值得关注。
- 💡 认为M4 Ultra及以后产品将针对LLMs优化
- 解释:基于现在可以在苹果神经引擎上运行模型,推测未来产品会有针对LLMs的优化。
金句与有趣评论
- “😂 SporksInjected: This is awesome. This means you can effectively leave a small model loaded in ram for terminal completions and its virtually transparent on desktop and completely usable on battery.”
- 亮点:生动地阐述了在Mac神经引擎运行模型对于终端补全在不同场景下的可行性。
- “🤔 另一个7B 4bit基准,其优化程度较低(带宽无法反映高级机器的速度)。”
- 亮点:对7B 4bit基准测试的优化情况给出见解。
- “👀 从X 关于anemll llama的量化:“It’s in meta.yalm file,FFN and refill are 6 bit LUT””
- 亮点:提供了Anemll llama量化方面的技术信息。
- “🤔 我一直想知道为什么不是这样,考虑到苹果在宣传和营销他们的神经引擎等方面领先其他人很多年。”
- 亮点:对之前不能在苹果神经引擎运行模型表示疑惑并结合苹果宣传情况。
- “😂 忽略我;我很愚蠢。”
- 亮点:体现评论者对自己之前言论的反悔态度,较为有趣。
情感分析
总体情感倾向是积极的。主要分歧点在于对功率消耗降低这一成果的重视程度,部分人认为这是在Mac神经引擎上运行模型的优势,而有人认为在AI领域功率消耗不是最应担忧的。可能的原因是不同人对人工智能发展中不同性能指标的关注度不同。
趋势与预测
- 新兴话题:M4 Ultra及后续产品对LLMs的优化,以及在Apple Vision Pro上是否能实现模型运行。
- 潜在影响:如果更多在苹果和高通NPUs上运行LLMs取得成功,可能促使芯片制造商和操作系统开发者加大投入,推动相关技术发展,改变人们使用本地模型的方式等。
详细内容:
标题:Mac 现可在神经引擎上运行模型,引发热烈讨论
在 Reddit 上,一则关于“Mac 现可在神经引擎上运行模型”的帖子引起了广泛关注。该帖子介绍了Anemll,称其能让用户在神经引擎上直接运行模型,与在 GPU 上运行的 lm studio 或 ollama 相比,能耗大幅降低。比如,运行 llama-3.2-1b 时,功率从 GPU 上的 8W 降至 1.7W,每秒处理事务数(TPS)虽略有下降,从 56 次/秒降至 45 次/秒。帖子还提到 Anemll 模型的上下文限制为 512,不确定是神经引擎的限制还是尚未转换更大的模型。若想尝试,可前往其huggingface并按照说明操作。
此贴获得了众多点赞和大量评论,引发的主要讨论方向包括对模型性能、未来发展以及不同硬件设备支持的探讨。
讨论焦点与观点分析: 有人指出,若能实现仅整数计算范式,对 NPUs 来说将大幅提升处理能力。有人认为当前世代的 NPUs 并非专为 LLMs 设计,未来世代会有所改进。还有人觉得这个技术很棒,意味着可以在内存中加载小模型用于终端完成任务,在桌面上几乎无影响,在电池供电下也完全可用。
有人表示,如果典型的开发程序如 fish、vscode 等能采用简便方式与 LLMs 通过 NPU 交互,会每天使用。也有人提到希望未来 12 个月左右能在 NPU 上运行本地 7B 不太量化的模型,具有与现今大型 sota 编码器模型相同的智商和上下文大小。
有人认为 ANE 在性能上领先于 Qualcomm NPU,但开发难度较大,存在诸多限制。对于该技术是否适用于 Apple Vision Pro 存在疑问。
有人觉得能耗并非 AI 的首要担忧,更希望苹果提供带宽更高的芯片。
特别有见地的观点如,更多在 Apple 和 Qualcomm NPUs 上的成功意味着芯片制造商和操作系统制造商将更关注让 LLMs 在这些 NPUs 上可用。
讨论中的共识在于,大家普遍认为这一技术具有潜力,尽管存在一些限制和问题,但有望成为未来运行本地 llms 的重要方式。
这一讨论展现了大家对新技术的期待和对其发展方向的思考。


感谢您的耐心阅读!来选个表情,或者留个评论吧!