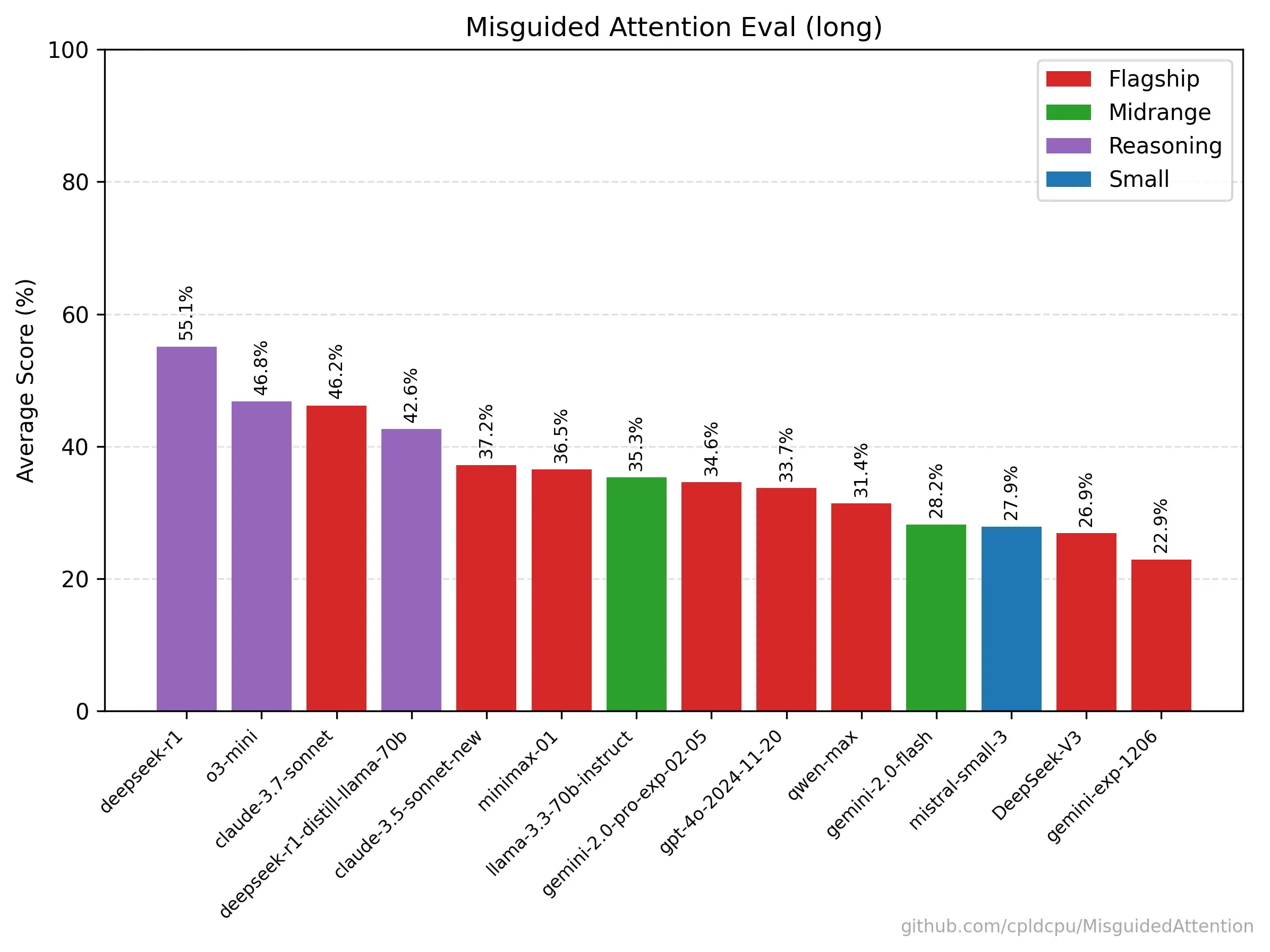
“误导性注意力”(https://github.com/cpldcpu/MisguidedAttention)是一组提示,用于在存在误导性信息的情况下挑战大型语言模型的推理能力。它由经过轻微修改的著名逻辑问题和谜题组成。许多模型对这些问题过度拟合,因此会对未修改的问题给出响应。Claude - 3.7 - Sonnet在长评估中的非思考模式下,使用52个提示进行了评估。尽管没有使用思考模式,但它几乎击败了o3 - mini,这是一个非常令人印象深刻的结果。一旦我弄清楚如何在OpenRouter API中激活思考模式,我将对其进行基准测试。
讨论总结
原帖提到Claude - 3.7 - Sonnet在非思考模式下的基准测试结果,很多评论者围绕此展开讨论。有人对基准测试表示喜爱和感谢,也有人对模型表现好的原因存疑,还有人对不同模型进行比较,讨论模型是否被低估,也涉及到模型的思考模式、过拟合等问题,同时还有关于编程、版本期待等话题的讨论,整体氛围积极且大家都在积极探索相关话题。
主要观点
- 👍 对基准测试表示喜爱并感谢快速测试
- 支持理由:原帖快速进行基准测试,评论者认可这一工作
- 反对声音:无
- 🔥 质疑模型表现好的原因难以判断
- 正方观点:无法分辨模型表现好是未对标准版本谜题过度拟合还是针对基准版本训练
- 反方观点:原帖作者认为已打乱数据集且未发现针对此基准训练的证据
- 💡 minimax - o1被严重低估
- 正方观点:认为其基础比V3和Qwen好(过拟合问题上),在长文本语境下表现好
- 反方观点:无
- 🤔 对3.7版本训练方向转变感到兴奋
- 支持理由:认为从竞争编程转向现实世界问题会让3.7版本在实际编程表现更好
- 反对声音:无
- 😎 希望对DeepSeek Distill Qwen 32B进行测试
- 支持理由:未阐述,只是表达希望测试该模型
- 反对声音:无
金句与有趣评论
- “😂 Thanks for benchmarking it so fast, I like this benchmark!”
- 亮点:表达对原帖快速进行基准测试的感谢与喜爱
- “🤔 I also like this benchmark very much. The sad thing is that we can’t tell if some models perform well because they didn’t overfit on the standard versions of those riddles, or because they trained on the benchmark versions.”
- 亮点:指出难以判断模型表现好的原因
- “👀 R1 is a monster.”
- 亮点:用简洁话语表明R1的强大
- “😎 What I’m excited to try is they said that they have steered away from training on competitive coding to focus more on real - world issues.”
- 亮点:表达对3.7版本训练方向转变的兴奋
- “🤔 minimax - o1 feels like its seriously underrated.”
- 亮点:提出minimax - o1被严重低估的观点
情感分析
总体情感倾向积极。主要分歧点在于模型表现好的原因上,一方认为难以判断是未过度拟合标准版本还是针对基准版本训练,另一方认为已打乱数据集且无针对基准训练的证据。可能原因是大家对模型训练机制、数据集等背景知识的了解程度不同,以及对测试结果解读的角度差异。
趋势与预测
- 新兴话题:对不同模型进行更多测试,如DeepSeek Distill Qwen 32B。
- 潜在影响:对模型开发方向产生影响,如训练方向从竞争编程转向现实世界问题可能促使更多模型效仿,从而提高模型在实际编程中的表现。
详细内容:
标题:Sonnet-3.7 在 Misguided Attention 评估中的出色表现引发热议
近日,Reddit 上一则关于“Sonnet-3.7 是 Misguided Attention 评估中表现最佳的非思考模型”的帖子引发了广泛关注。该帖子介绍了 Misguided Attention 是一系列用于挑战大型语言模型在误导信息存在时推理能力的提示集合,包含了略微修改过的知名逻辑问题和谜语。帖子称,Claude-3.7-Sonnet 在非思考模式下经过 52 个提示的长期评估,表现出色,几乎击败了 o3-mini,尽管它未使用思考模式。此帖获得了众多点赞和评论。
讨论的焦点主要集中在以下几个方面: 有人对是否尝试“扩展思考”模式提出疑问,而作者表示尚未在 openrouter 中弄清楚如何激活。也有人表示在 openrouter 上还未看到相关选项,猜测还需等待。 还有人喜欢这个评估,同时也指出难以判断某些模型表现好是因为未对标准版本的谜语过度拟合,还是因为训练了基准版本。有人认为存在一个市场,需要高质量且像核机密一样被守护、绝不以任何形式公布的专有基准。 对于模型的评价,有人认为 minimax-o1 被严重低估,其基础比 V3 和 Qwen 更好,在长上下文方面表现出色,甚至基础模型也很健谈。有人因为 Claude 感觉智商高而使用它。也有人好奇 3.7 思考模式相较 3.7 的优势。
在讨论中,大家观点各异,有人认为 Sonnet-3.7 的出色表现令人惊喜,也有人对评估的准确性和模型的实际应用提出了思考。但总体来说,大家对语言模型的发展和评估充满了关注和期待。


感谢您的耐心阅读!来选个表情,或者留个评论吧!