Karpathy发布的内容:[https://xcancel.com/karpathy/status/1894923254864978091](涵盖了关于图像/视频与文本方面变换器与扩散之间一些有趣的细微差别)。人工分析比较:[
讨论总结
该讨论围绕一个基于扩散的小型编码LLM展开。这个模型在令牌生成速度上比基于变压器的LLM快10倍。人们从多个方面对其进行讨论,包括性能测试、与其他模型对比、效率如何、模型是否开源、在本地运行的硬件需求等。既有对模型积极尝试并认可的声音,也有对模型表示怀疑和提出问题的评论,整体讨论氛围积极且充满好奇探索的态度。
主要观点
- 👍 对在小编码任务中的表现给予肯定
- 支持理由:在一些小的编码任务中输出正确且速度快。
- 反对声音:未涉及。
- 🔥 对新LLM不共享权重和推理代码的疑惑
- 正方观点:若方法好,应分享底层原理以便他人重现。
- 反方观点:未涉及。
- 💡 认为这个基于扩散的编码LLM很令人兴奋
- 支持理由:令牌生成速度快,可能对解决人工智能现存问题有帮助。
- 反对声音:未涉及。
- 🤔 对模型在复杂编码任务中的表现未知
- 支持理由:尚未在非常复杂的编码问题上进行测试。
- 反对声音:未涉及。
- 😕 关注模型的准确性
- 支持理由:速度快不代表准确性高,需要基准测试和评估内容。
- 反对声音:未涉及。
金句与有趣评论
- “😂 I’m going to guess the DeepSeek geniuses will be all over this and will release something with open source weights/inference code.”
- 亮点:对开源工作进行猜测,反映对模型开源的期待。
- “🤔 I wonder if this also help with hallucination or reducing noise?”
- 亮点:对新技术在解决人工智能现存问题方面的期待。
- “👀 Here’s my take: llada does not seem to be efficient in its current format. Requires very high NFEs and a bunch of complicated masking strategies. But this work is also too good to be true. It’s 10 times faster at the cost of what. At least put a technical report out there.”
- 亮点:对新模型效率提出质疑,要求发布技术报告。
- “😎 I was wondering. If I understand correctly, unlike typical LLM that just generates output token - by - token and can just run, producing output of arbitrary length, diffusion models operate on latent noise of fixed dimensions.”
- 亮点:指出扩散模型与典型LLM的运行差异。
- “😊 Okay this is cool. It never occurred to me to question why we have diffusion models for images but not text. Thanks for sharing!”
- 亮点:表达对新出现的文本扩散模型相关内容的惊喜和感激。
情感分析
总体情感倾向是积极好奇的。主要分歧点在于对模型的性能(如准确性、代码质量)和工作方式(如扩散模型如何适应文本生成)的不同看法。可能的原因是大家从不同的使用场景和需求出发,以及对新技术的理解程度不同。
趋势与预测
- 新兴话题:扩散模型如何在文本生成任务中更好地发挥作用,不同架构模型在本地运行的优化。
- 潜在影响:如果这些基于扩散的模型发展良好,可能会改变现有的语言模型格局,影响人工智能在编码、文本处理等领域的应用方式。
详细内容:
标题:关于新型编码 LLM 的热门讨论
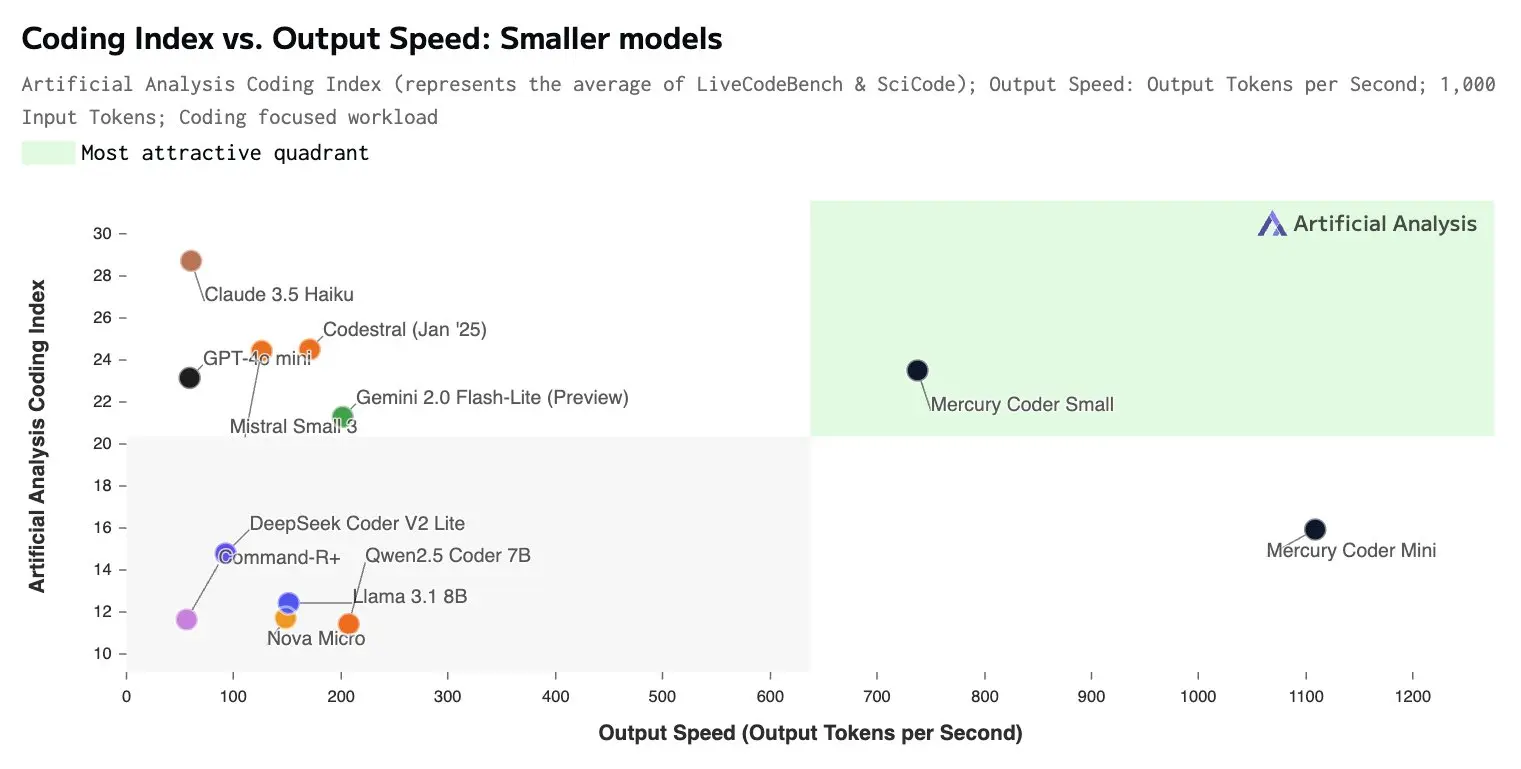
最近,Reddit 上有一个关于新型编码语言模型(LLM)的帖子引起了广泛关注。这个被称为“基于扩散的‘小型’编码 LLM”的模型声称在令牌生成速度上比基于变压器的 LLM 快 10 倍,达到了惊人的 1000 令牌/秒(在 H100 上)。该帖子获得了大量的点赞和众多评论。
主要的讨论方向包括:这个模型的性能到底如何,与其他模型相比的优势和不足,是否为开源,以及其在不同应用场景中的表现等。
讨论焦点与观点分析:
有人指出 llada 与这个新模型无关,这个新模型是一家初创公司的成果,且为闭源。有人在尝试后表示印象深刻,比如能够快速准确地生成各种小型编码任务的代码。但也有人发现其在处理某些复杂问题时表现不佳,甚至逻辑推理性能也有待提升。
有用户认为扩散模型在某些方面的表现优于现有的模型,例如在生成速度和纠正错误的能力上,但与某些先进模型如 Claude 3.7 相比,仍存在差距。
有人好奇这个模型的参数数量以及它的训练所需的计算量和成本。
还有用户探讨了扩散模型与变压器模型的关系,以及扩散模型在文本生成任务中的适应性和工作原理。
特别有见地的观点如,有人认为如果该模型能够在较小的硬件上运行,可能会解决硬件昂贵且难以获取的问题。
总之,关于这个新型编码 LLM 的讨论十分热烈,各方观点各异,展现了大家对新技术的关注和思考。但目前对于其性能和应用前景,仍需更多的测试和评估来得出准确结论。


感谢您的耐心阅读!来选个表情,或者留个评论吧!