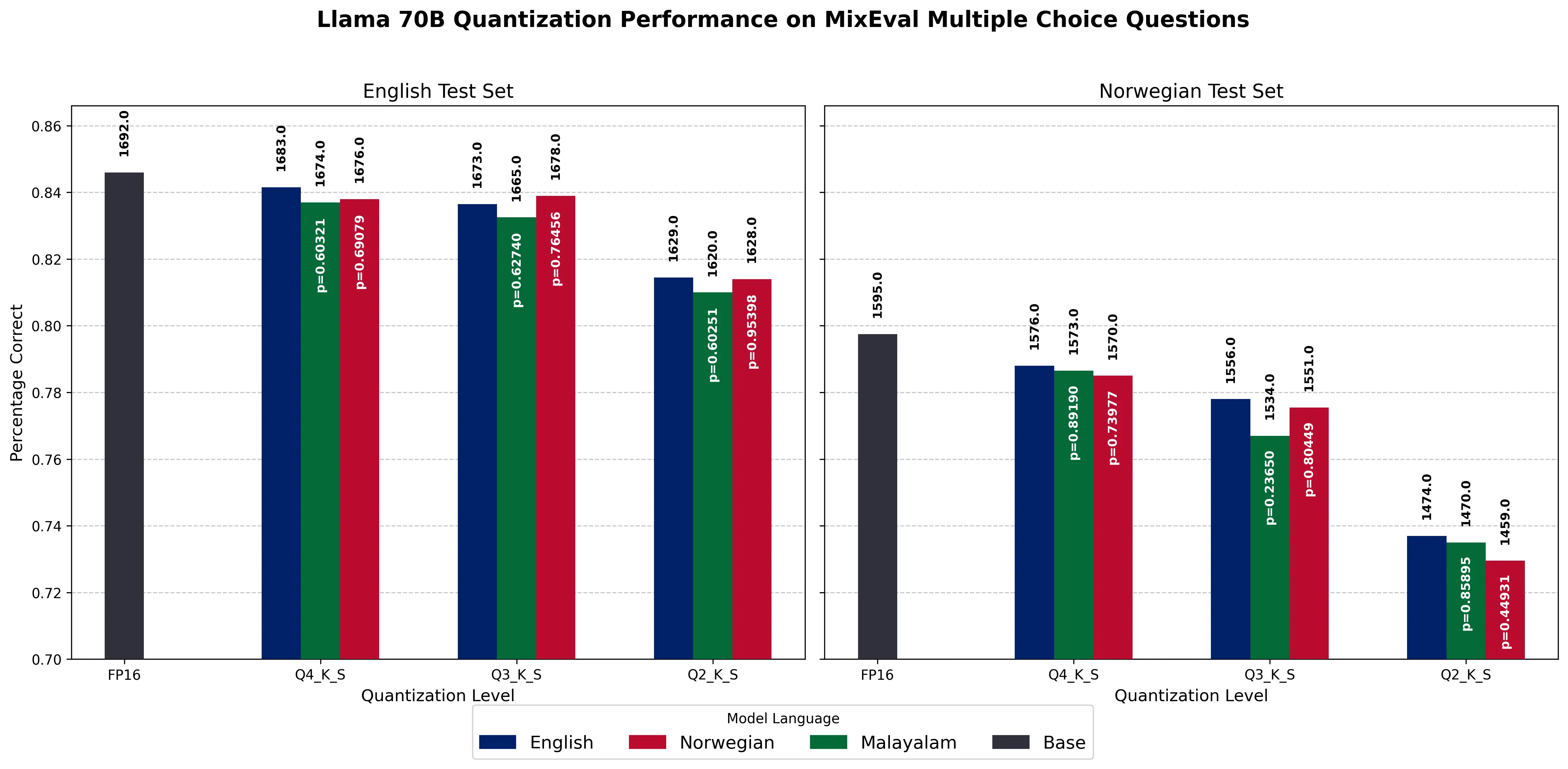
我应该更乐于公开负面(正面?)结果,所以在此公布。简而言之:.gguf格式的量化通常通过重要性矩阵完成,该矩阵计算每个权重对大型语言模型(LLM)的重要性。我曾认为,基于不同语言重要性矩阵对模型进行量化(毫不奇怪,我们在网上找到的量化模型几乎总是基于英语重要性矩阵构建的)可能对多语言性能的损害较小,但结果并不支持这一观点。实际上,基于这些替代重要性矩阵的量化可能会对其有轻微损害,尽管这些结果在统计上并不显著。
讨论总结
原帖发布了关于量化对多语言大型语言模型(LLMs)影响的研究结果,包括基于不同语言重要性矩阵的量化实验等内容,并希望得到对论文写作的建议。评论者们反应多样,有推荐相关论文的,有表示测试结果与自己相符的,有对原帖中统计显著性的提及表示赞赏的,有对原帖内容提出质疑的,还有对量化方法进行对比探讨的,以及提出新的研究提议和资源资助的等。整体氛围比较积极,大家围绕原帖的研究展开了不同层次的交流。
主要观点
- 👍 推荐《How Does Quantization Affect Multilingual LLMs?》论文
- 支持理由:如果对原帖话题感兴趣值得一看,论文深入探讨量化对多语言LLMs影响且研究规模较大还有人工评估内容。
- 反对声音:无。
- 🔥 原帖测试结果与自己之前测试相符
- 正方观点:结果显示高噪音程度。
- 反方观点:无。
- 💡 认可原作者考虑统计显著性,但未被完全说服
- 正方观点:统计显著性常被忽视,原作者考虑到这点很好。
- 反方观点:自己习惯避免使用imatrix quants,原作者的工作虽有影响但不足以完全改变自己想法。
- 🤔 I - quants比K - quants在3位及以下时更好
- 正方观点:有github链接为依据。
- 反方观点:原帖作者尝试得到类似结果,因花费时间多停止探索。
- 😎 不论语言,多数重要权重相同
- 支持理由:如果这个假设成立,原帖结果合理。
- 反对声音:无。
金句与有趣评论
- “😂 如果这是你感兴趣的话题,我也强烈推荐这篇论文《How Does Quantization Affect Multilingual LLMs?》https://arxiv.org/pdf/2407.03211。”
- 亮点:为对原帖话题感兴趣的人推荐相关论文资源。
- “🤔 它们与我之前的测试非常吻合,这也显示了结果数据中的高噪音程度。”
- 亮点:表明原帖测试结果与自己之前测试的关联性并指出结果数据特征。
- “👀 It’s great that you consider the almost always overlooked issue of statistical significance.”
- 亮点:对原作者考虑统计显著性给予肯定。
- “😎 我的理论一直是,不论语言,大部分重要权重保持相同。”
- 亮点:提出自己的理论假设并与原帖研究结果建立联系。
- “💡 noneabove1182: If you want to dive deeper into imatrix investigations, I had some ideas about testing new concepts, outside of just the one calibration set i use everywhere”
- 亮点:提出深入研究imatrix的新想法。
情感分析
总体情感倾向是积极的。主要分歧点在于原帖的研究成果是否足以改变部分评论者对imatrix quants的使用态度,以及原帖对数据集的调整是否影响翻译质量等。可能的原因是不同评论者的研究背景、关注重点和使用习惯不同。
趋势与预测
- 新兴话题:对imatrix的深入研究相关想法可能引发后续讨论。
- 潜在影响:可能会影响量化在多语言LLMs领域的应用和研究方向,对相关技术发展有一定推动作用。
详细内容:
标题:关于 LLMs 量化对多语言性能影响的热门讨论
在 Reddit 上,一篇题为“English K_Quantization of LLMs Does Not Disproportionately Diminish Multilingual Performance”的帖子引发了广泛关注。该帖子获得了众多点赞和大量评论。
原帖主要探讨了在.gguf 格式上的量化通常使用重要性矩阵来进行,作者原本认为基于不同语言重要性矩阵的量化对多语言性能的破坏性可能较小,但实验结果并不支持这一想法,且这些结果在统计学上并不显著。作者还提供了相关实验的链接,如[Results on MixEval multiple choice questions]、[Results on MixEval Free-form questions],并在 Arxiv 上发表了详细的论文[https://arxiv.org/abs/2503.03592]。
帖子引发的主要讨论方向包括对实验结果的分析、不同量化方案的比较以及对多语言模型中语言处理机制的探讨等。
文章将要探讨的核心问题是:如何准确评估量化方案对多语言大型语言模型性能的影响,以及如何在不同语言之间找到更优化的量化策略。
讨论焦点与观点分析
有人分享道:“感谢分享这些重要性矩阵测试结果。它们与我之前的测试结果相符,也显示出了结果数据中的高度噪声。很高兴看到您在展示结果的同时提到了统计显著性,这在如今发布最新量化方案基准测试时经常被遗忘。”
还有人指出:“首先,感谢您的工作。我对这个话题非常感兴趣,所以每一点额外的信息都很有价值。您能考虑到几乎总是被忽视的统计显著性问题,这很棒。不过,我还是尽量避免使用重要性矩阵量化,只有在别无选择时才会使用。您的工作可能会促使我朝这个方向思考,但我仍未完全信服。”
也有人认为:“MixEval 对于特定应用,如使用母语与 LLM 交互,是一个很好的指标。但我主要对翻译感兴趣,您在准备数据集时所做的一些调整可能会降低语言理解,从而影响翻译质量。”
有人提到:“我的理论一直是,无论语言如何,大多数重要权重都是相同的。如果我们基于英语语料库进行修剪,可能会破坏多语言性能。但由于重要性矩阵只是提升重要权重,同时只是稍微牺牲不太重要的权重,因此对整个模型的影响不会很大。”
对于量化方案的选择,有人提出疑问:“为什么不使用 I-quants?它们在 3 位及以下比 K-quants 要好得多:https://github.com/ggml-org/llama.cpp/pull/5747 。”
有人回应道:“我尝试过一些 I-quants,观察到的结果与我所描述的相似,而且在这个项目上已经花费了太多时间,所以就到此为止。”
讨论中的共识在于对实验结果的重视以及对多语言模型量化问题的深入思考。特别有见地的观点是对于不同语言权重相似性的理论探讨,以及对数据集调整可能影响翻译质量的分析,这些观点丰富了对多语言模型量化问题的理解。


感谢您的耐心阅读!来选个表情,或者留个评论吧!