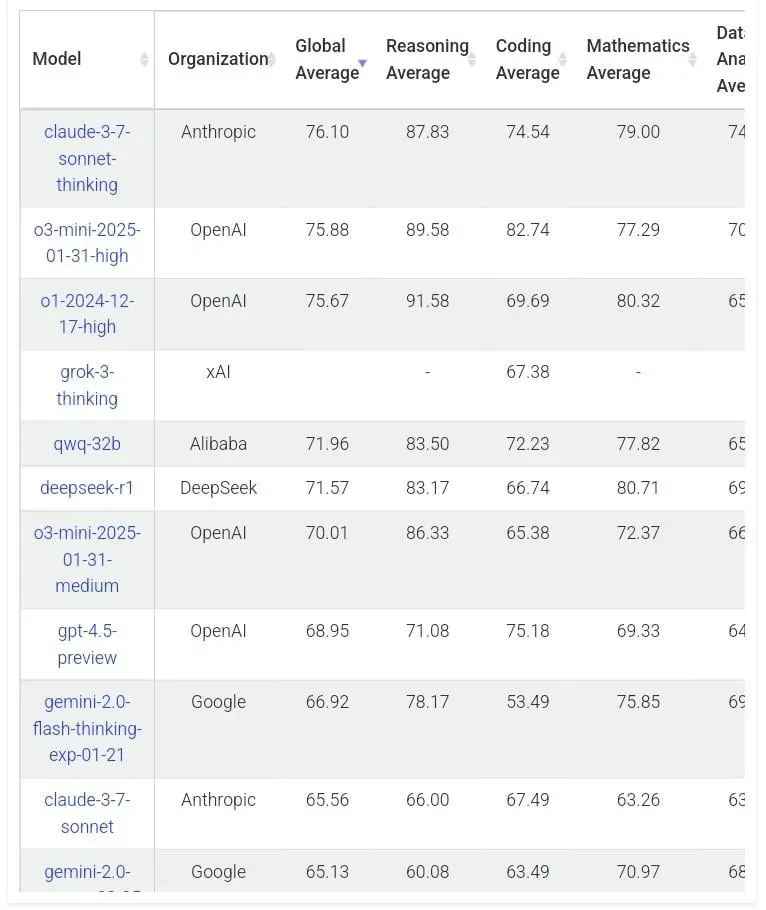
完整结果链接:Livebench,
讨论总结
这是一个关于Qwq - 32b更新Livebench的讨论。评论者们从不同角度发表看法,包括模型的性能表现(如在编码方面与其他模型的比较)、对不同模型发展趋势的见解(大型旗舰模型遇瓶颈,小型模型变强)、开源话题(中美模型开源模式差异)、本地运行的发展态势以及对特定模型(如Deepseek R2)的期待等,同时也有对Qwq - 32b结果的质疑。
主要观点
- 👍 Qwq - 32b的排名是实至名归的,是用过的最好的本地编码模型
- 支持理由:在有多种显存选择情况下仍觉得该模型好。
- 反对声音:有评论者认为在编码方面不如R1。
- 🔥 大型旗舰模型遇到发展瓶颈,小型模型变得日益强大
- 正方观点:小型模型发展有利于本地运行任务,带来更多可能。
- 反方观点:无明显反方观点。
- 💡 中国的工作方式是免费发布模型,通过制造硬件盈利
- 解释:阐述中国模型开源与硬件盈利的模式,区别于美国为企业利润不开源模型。
- 🤔 qwq - 32b在部分方面优于R1,过去一周使用qwq - 32b体验良好
- 支持理由:使用体验佳且在基准测试表现良好。
- 反对声音:有评论者在编码测试中发现其不如R1。
- 😕 Qwq - 32b存在过度思考的情况,复杂问题思考时间过长导致难以使用
- 支持理由:有用户反映除非问题简单,否则至少思考3 - 5分钟。
- 反方观点:可以通过一些方式解决,如更新模型版本、调整参数。
金句与有趣评论
- “😂 我记得当OpenAI组织与政府官员开会是因为他们发现了O1。六个月后,我们就可以免费在3090上使用O3 - mini了。”
- 亮点:回顾OpenAI相关事件及后续模型的免费使用情况,展示模型发展历程中的关联事件。
- “🤔 ShinyAnkleBalls: I am not regretting dropping my OpenAI subscription.”
- 亮点:表达对qwq - 32b的认可,宁愿放弃OpenAI订阅。
- “👀 大型旗舰模型似乎遇到了瓶颈,而小型模型变得越来越强大 - 这对本地运行来说是一个很好的发展。”
- 亮点:指出模型发展的趋势以及对本地运行的积极意义。
- “😎 Well deserved ranking.”
- 亮点:简洁地表达对Qwq - 32b排名的认可。
- “🤨 Is the QWQ - 32B model provided by Groq the same one people can run at home?”
- 亮点:对QWQ - 32B模型是否为家用模型提出疑问,引发对模型使用场景的思考。
情感分析
总体情感倾向较为复杂。有积极正面的情感,如对Qwq - 32b性能的认可、对其更新带来效果的赞赏以及对小型模型发展趋势的看好;也存在质疑和负面的情感,如对Qwq - 32b结果的怀疑(可能是过度拟合、成绩不真实等)、对其在编码方面不如其他模型的看法以及对它过度思考问题的不满。主要分歧点在于Qwq - 32b的性能和成绩的真实性,可能是因为不同用户使用场景、测试方法和期望不同导致。
趋势与预测
- 新兴话题:对模型如Deepseek R2的期待,可能会引发更多关于它的性能、能否设立新标准的讨论。
- 潜在影响:如果小型模型持续发展强大,可能会改变人们使用模型的方式,更多依赖本地运行任务,减少对商业大型语言模型的依赖;对模型性能、开源方式等方面的讨论也可能影响相关企业或开发者对模型的改进和发展方向。
详细内容:
标题:Qwq-32b 模型更新引发 Reddit 热议
最近,Reddit 上关于 Qwq-32b 模型更新的话题备受关注,相关帖子获得了大量的点赞和众多评论。原帖提供了 Livebench 的链接Livebench,还配有一张图片,但因连接错误未能成功展示。
这一话题引发了广泛而热烈的讨论,主要观点包括:有人认为 Qwq-32b 模型在某些方面表现出色,比如有人分享自己过去一周使用该模型的良好体验,甚至有人因此放弃了 OpenAI 的订阅;但也有人指出其存在的问题,比如在某些编程语言的处理上不如其他模型,容易陷入过度思考的情况。
有用户提到:“作为一名在相关领域工作的人员,我记得当 OpenAI 组织与政府官员的会议时,因为他们发现了 O1。 六个月后,我们在 3090 上就能免费使用 O3 - mini 了。”还有用户说:“中国的运作方式不同,他们会免费发布模型,然后对运行此模型的超高速硬件收费。”
有人对该模型的创新能力感到惊讶,认为它能很好地模仿人类,思维过程很“真实”。但也有人质疑所谓“真实”的具体含义。
对于 Qwq-32b 模型与其他模型的比较,看法各异。有人觉得它在某些基准测试中表现优于 R1,也有人认为在编码方面 R1 表现更好,做出的报告更出色。
关于模型的适用性,有人认为其在商业大语言模型中的主要用途是搜索,而很多其他需求可以在本地解决。
有人期待着 Deepseek R2 能设定新的标准,也有人对 Qwq-32b 模型是否真的如宣传的那样优秀表示怀疑,认为需要公布具体的设置和参数,并进行权威的基准测试来验证。
在这场讨论中,既有对 Qwq-32b 模型的赞美和期待,也有对其不足的审视和质疑。究竟 Qwq-32b 模型能否在竞争激烈的模型市场中脱颖而出,还需进一步观察和实践的检验。


感谢您的耐心阅读!来选个表情,或者留个评论吧!